The REPLACE DISK command was released with 12.1 and allow to do an online replacement for a failed disk. This command is important because it reduces the rebalance time doing just the SYNC phase. Comparing with normal disk replacement (DROP and ADD in the same command), the REPLACE just do mirror resync.
Basically, when the REPLACE command is called, the rebalance just copy/sync the data from the survivor disk (the partner disk from the mirror). It is faster since the previous way with drop/add execute a complete rebalance from all AU of the diskgroup, doing REBALANCE and SYNC phase.
The replace disk command is important for the SWAP disk process for Exadata (where you add the new 14TB disks) since it is faster to do the rebalance of the diskgroup.
Below one example from this behavior. Look that AU from DISK01 was SYNCED with the new disk:
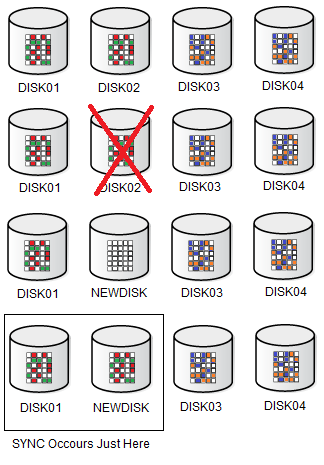
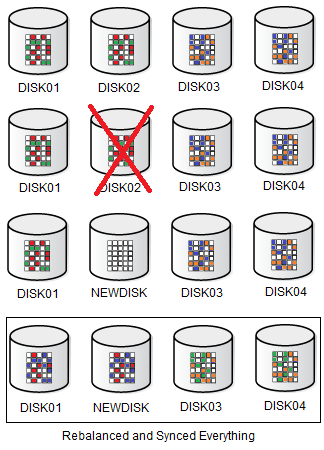
And compare with the previous DROP/ADD disk, where all AU from all disks was rebalanced:
Actual Environment And Simulate The failure
In this post, to simulate and show how the replace disk works I have the DATA diskgroup with 6 disks (DISK01-06). The DISK07 it is not in use.
SQL> select NAME,FAILGROUP,LABEL,PATH from v$asm_disk order by FAILGROUP, label;
NAME FAILGROUP LABEL PATH
------------------------------ ------------------------------ ---------- -----------
DISK01 FAIL01 DISK01 ORCL:DISK01
DISK02 FAIL01 DISK02 ORCL:DISK02
DISK03 FAIL02 DISK03 ORCL:DISK03
DISK04 FAIL02 DISK04 ORCL:DISK04
DISK05 FAIL03 DISK05 ORCL:DISK05
DISK06 FAIL03 DISK06 ORCL:DISK06
RECI01 RECI01 RECI01 ORCL:RECI01
SYSTEMIDG01 SYSTEMIDG01 SYSI01 ORCL:SYSI01
DISK07 ORCL:DISK07
9 rows selected.
SQL>
And to simulate the error I disconnected the disk from Operational system (since I used iSCSI, I just log off the target for DISK02:
[root@asmrec ~]# iscsiadm -m node -T iqn.2006-01.com.openfiler:tsn.eff4683320e8 -p 172.16.0.3:3260 -u Logging out of session [sid: 41, target: iqn.2006-01.com.openfiler:tsn.eff4683320e8, portal: 172.16.0.3,3260] Logout of [sid: 41, target: iqn.2006-01.com.openfiler:tsn.eff4683320e8, portal: 172.16.0.3,3260] successful. [root@asmrec ~]#
At the same moment, the alertlog from ASM detected the error and informed that the mirror was found in another disk (DISK06):
2020-03-29T00:42:11.160695+01:00
WARNING: Read Failed. group:3 disk:1 AU:29 offset:0 size:4096
path:ORCL:DISK02
incarnation:0xf0f0c113 synchronous result:'I/O error'
subsys:/opt/oracle/extapi/64/asm/orcl/1/libasm.so krq:0x7f3df8db35b8 bufp:0x7f3df8c9c000 osderr1:0x3 osderr2:0x2e
IO elapsed time: 0 usec Time waited on I/O: 0 usec
WARNING: cache failed reading from group=3(DATA) fn=8 blk=0 count=1 from disk=1 (DISK02) mirror=0 kfkist=0x20 status=0x02 osderr=0x3 file=kfc.c line=13317
WARNING: cache succeeded reading from group=3(DATA) fn=8 blk=0 count=1 from disk=5 (DISK06) mirror=1 kfkist=0x20 status=0x01 osderr=0x0 file=kfc.c line=13366
So, at this moment the DQISK02 will not be removed instantely, but after the disk_repair_time finish:
WARNING: Started Drop Disk Timeout for Disk 1 (DISK02) in group 3 with a value 43200
WARNING: Disk 1 (DISK02) in group 3 will be dropped in: (43200) secs on ASM inst 1
cluster guid (e4db41a22bd95fc6bf79d2e2c93360c7) generated for PST Hbeat for instance 1
So, at this moment the DQISK02 will not be removed instantly, but after the disk_repair_time finish:
WARNING: Started Drop Disk Timeout for Disk 1 (DISK02) in group 3 with a value 43200 WARNING: Disk 1 (DISK02) in group 3 will be dropped in: (43200) secs on ASM inst 1 cluster guid (e4db41a22bd95fc6bf79d2e2c93360c7) generated for PST Hbeat for instance 1
If you want to check the full output from ASM alertlog you can access here at ASM-ALERTLOG-Output-Online-Disk-Error.txt
So, the actual diskgroup is:
SQL> select NAME,FAILGROUP,LABEL,PATH from v$asm_disk order by FAILGROUP, label;
NAME FAILGROUP LABEL PATH
------------------------------ ------------------------------ ---------- -----------
DISK01 FAIL01 DISK01 ORCL:DISK01
DISK02 FAIL01
DISK03 FAIL02 DISK03 ORCL:DISK03
DISK04 FAIL02 DISK04 ORCL:DISK04
DISK05 FAIL03 DISK05 ORCL:DISK05
DISK06 FAIL03 DISK06 ORCL:DISK06
RECI01 RECI01 RECI01 ORCL:RECI01
SYSTEMIDG01 SYSTEMIDG01 SYSI01 ORCL:SYSI01
DISK07 ORCL:DISK07
9 rows selected.
SQL>
REPLACE DISK
Since the old disk was lost (by HW or something similar), it is impossible to put it again online. A new disk was attached to the server (DISK07 in this example) and this is added in the diskgroup.
So, we just need to execute the REPLACE DISK command:
SQL> alter diskgroup DATA 2 REPLACE DISK DISK02 with 'ORCL:DISK07' 3 power 2; Diskgroup altered. SQL>
The command is easy, we replace disk failed disk with the new disk path. And it is possible to replace more than one at the same time and specify the power of the rebalance too.
At ASM alertlog we can see a lot of messages about this replacement, but look that resync of the disk. The full output can be found here at ASM-ALERTLOG-Output-Replace-Disk.txt
Some points here:
2020-03-29T00:44:31.602826+01:00 SQL> alter diskgroup DATA replace disk DISK02 with 'ORCL:DISK07' power 2 2020-03-29T00:44:31.741335+01:00 NOTE: cache closing disk 1 of grp 3: (not open) DISK02 2020-03-29T00:44:31.742068+01:00 NOTE: GroupBlock outside rolling migration privileged region 2020-03-29T00:44:31.742968+01:00 NOTE: client +ASM1:+ASM:asmrec no longer has group 3 (DATA) mounted 2020-03-29T00:44:31.746444+01:00 NOTE: Found ORCL:DISK07 for disk DISK02 NOTE: initiating resync of disk group 3 disks DISK02 (1) NOTE: process _user20831_+asm1 (20831) initiating offline of disk 1.4042309907 (DISK02) with mask 0x7e in group 3 (DATA) without client assisting 2020-03-29T00:44:31.747191+01:00 NOTE: sending set offline flag message (2044364809) to 1 disk(s) in group 3 … … 2020-03-29T00:44:34.558097+01:00 NOTE: PST update grp = 3 completed successfully 2020-03-29T00:44:34.559806+01:00 SUCCESS: alter diskgroup DATA replace disk DISK02 with 'ORCL:DISK07' power 2 2020-03-29T00:44:36.805979+01:00 NOTE: Attempting voting file refresh on diskgroup DATA NOTE: Refresh completed on diskgroup DATA. No voting file found. 2020-03-29T00:44:36.820900+01:00 NOTE: starting rebalance of group 3/0xf99030d7 (DATA) at power 2
After that, we can see the rebalance just take the SYNC phase:
SQL> select * from gv$asm_operation;
INST_ID GROUP_NUMBER OPERA PASS STAT POWER ACTUAL SOFAR EST_WORK EST_RATE EST_MINUTES ERROR_CODE CON_ID
---------- ------------ ----- --------- ---- ---------- ---------- ---------- ---------- ---------- ----------- ---------- ----------
1 3 REBAL COMPACT WAIT 2 2 0 0 0 0 0
1 3 REBAL REBALANCE WAIT 2 2 0 0 0 0 0
1 3 REBAL REBUILD WAIT 2 2 0 0 0 0 0
1 3 REBAL RESYNC RUN 2 2 231 1350 513 2 0
SQL>
SQL> /
INST_ID GROUP_NUMBER OPERA PASS STAT POWER ACTUAL SOFAR EST_WORK EST_RATE EST_MINUTES ERROR_CODE CON_ID
---------- ------------ ----- --------- ---- ---------- ---------- ---------- ---------- ---------- ----------- ---------- ----------
1 3 REBAL COMPACT WAIT 2 2 0 0 0 0 0
1 3 REBAL REBALANCE WAIT 2 2 0 0 0 0 0
1 3 REBAL REBUILD WAIT 2 2 0 0 0 0 0
1 3 REBAL RESYNC RUN 2 2 373 1350 822 1 0
SQL>
SQL> /
INST_ID GROUP_NUMBER OPERA PASS STAT POWER ACTUAL SOFAR EST_WORK EST_RATE EST_MINUTES ERROR_CODE CON_ID
---------- ------------ ----- --------- ---- ---------- ---------- ---------- ---------- ---------- ----------- ---------- ----------
1 3 REBAL COMPACT REAP 2 2 0 0 0 0 0
1 3 REBAL REBALANCE DONE 2 2 0 0 0 0 0
1 3 REBAL REBUILD DONE 2 2 0 0 0 0 0
1 3 REBAL RESYNC DONE 2 2 1376 1350 0 0 0
SQL> /
no rows selected
SQL>
In the end, after the rebalance we have:
SQL> select NAME,FAILGROUP,LABEL,PATH from v$asm_disk order by FAILGROUP, label; NAME FAILGROUP LABEL PATH ------------------------------ ------------------------------ ---------- ----------- DISK01 FAIL01 DISK01 ORCL:DISK01 DISK02 FAIL01 DISK07 ORCL:DISK07 DISK03 FAIL02 DISK03 ORCL:DISK03 DISK04 FAIL02 DISK04 ORCL:DISK04 DISK05 FAIL03 DISK05 ORCL:DISK05 DISK06 FAIL03 DISK06 ORCL:DISK06 RECI01 RECI01 RECI01 ORCL:RECI01 SYSTEMIDG01 SYSTEMIDG01 SYSI01 ORCL:SYSI01 8 rows selected. SQL>
An important detail is that the NAME for the disk will not change, it is impossible to change using REPLACE DISK command. As you can see above, the disk named DISK02 has the label DISK07 (here this came from asmlib disk).
Know Issues
There is a known issue for REPLACE DISK for 18c and higher for GI where the rebalance can take AGES to finish. This occurs because (when replacing more than one disk per time), it executes the SYNC disk by disk. One example, for one Exadata the replace for a complete cell took more than 48 hours, while a DROP/ADD took just 12 hours for the same disks.
So, it is recommended to have the fix for Bug 30582481 and Bug 31062010 applied. The detail it is that patch 30582481 (Patch 30582481: ASM REPLACE DISK COMMAND EXECUTED ON ALL CELLDISKS OF A FAILGROUP, ASM RUNNING RESYNC ONE DISK AT A TIME) was withdraw and replaced by bug/patch 31062010 that it is not available (at the moment that I write this port – March 2020).
So, be careful to do this in one engineering system or when you need to replace a lot of disks at the same time.
Some reference for reading:
Disclaimer: “The postings on this site are my own and don’t necessarily represent my actual employer positions, strategies or opinions. The information here was edited to be useful for general purpose, specific data and identifications were removed to allow reach the generic audience and to be useful for the community. Post protected by copyright.”
Pingback: Exadata, REQUIRED_MIRROR_FREE_MB and GRID 19.19 - Fernando Simon