Survive to disk failures it is crucial to avoid data corruption, but sometimes, even with redundancy at ASM, multiple failures can happen. Check in this post how to use the undocumented feature “mount restricted force for recovery” to resurrect diskgroup and lose less data when multiple failures occur.
Diskgroup redundancy is a key factor for ASM resilience, where you can survive to disk failures and still continue to run databases. I will not extend about ASM disk redundancy here, but usually, you can configure your diskgroup without redundancy (EXTERNAL), double redundancy (NORMAL), triple redundancy (HIGH), and even fourth redundancy (EXTEND for stretch clusters).
If you want to understand more about redundancy you have a lot of articles at MOS and on the internet that provide useful information. One good is this. The idea is simple, spread multiple copies in different disks. And can even be better if you group disks in the same failgroups, so, your data will have multiple copies in separate places.
As an example, this a key for Exadata, where every storage cell is one independent failgroup and you can survive to one entire cell failure (or double full, depending on the redundancy of your diskgroup) without data loss. The same idea can be applied at a “normal” environment, where you can create failgroup to disks attached to controller A, and another attached to controller B (so the failure of one storage controller does not affect all failgroups). At ASM, if you do not create failgroup, each disk is a different one in diskgroups that have redundancy enabled.
This represents for Exadata, but it is safe for representation. Basically your data will be in at least two different failgroups:
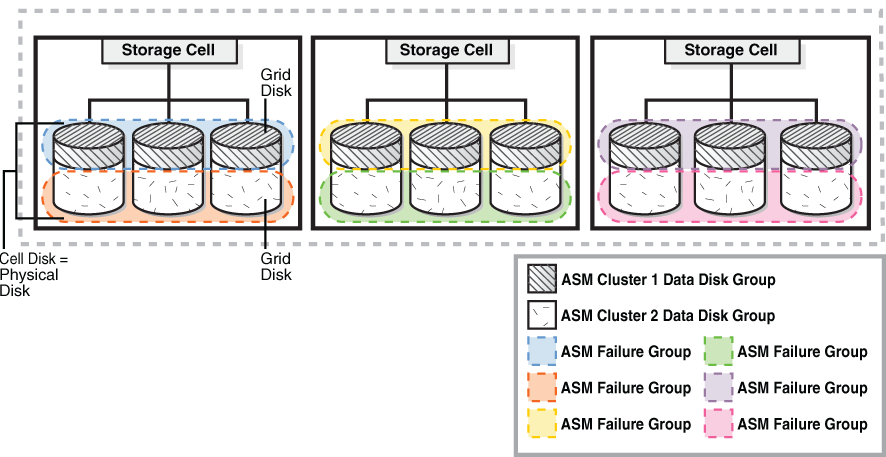
Environment
In the example that I use here, I have one diskgroup called DATA, which has 7 (seven) disks and each one is on failgroup. The redundancy for this diskgroup is NORMAL, this means that the block is copied in two failgroups. If two failures occur, probably, I will have data loss/corruption. Look:
SQL> select NAME,FAILGROUP,LABEL,PATH from v$asm_disk order by FAILGROUP, label; NAME FAILGROUP LABEL PATH ------------------------------ ------------------------------ ------------------------------- ------------------------------------------------------------ CELLI01 CELLI01 CELLI01 ORCL:CELLI01 CELLI02 CELLI02 CELLI02 ORCL:CELLI02 CELLI03 CELLI03 CELLI03 ORCL:CELLI03 CELLI04 CELLI04 CELLI04 ORCL:CELLI04 CELLI05 CELLI05 CELLI05 ORCL:CELLI05 CELLI06 CELLI06 CELLI06 ORCL:CELLI06 CELLI07 CELLI07 CELLI07 ORCL:CELLI07 RECI01 RECI01 RECI01 ORCL:RECI01 SYSTEMIDG01 SYSTEMIDG01 SYSI01 ORCL:SYSI01 9 rows selected. SQL>
The version for my GI is 19.6.0.0, but this can be used from 12.1.0.2 and newer versions (works for 11.2.0.4 in some versions). And In this server, I have three databases running, DBA19, DBB19, and DBC19.
So, with everything running correctly, the data from my databases will be spread two failgroups (this is just a representation and not correct representation where the blocks from my database are):

Remember that a NORMAL redundancy just needs two copies. So, some blocks from datafile 1 from DBA19, as an example, can be stored at CELLI01 and CELLI04. And if your database is small (and your failgroups are big), and you are lucky too, the entire database can be stored in just these two places. In case of failure that just involves CELLI02 and CELLI03 failgroups, your data (from DBA19c) can be intact.
Understanding the failure
Unfortunately, failures (will) happen and can be multiple at the same time. In the diskgroup DATA above, after the second failure, your diskgroup will be dismounted instantly. Usually when this occurs, if you can’t recover the hardware error, you need to restore and recover a backup of your databases after recreating the diskgroup.
If you have lucky and the failures occur at the same time, you can (most of the time) return the failed disks and try to mount the diskgroup because there is no difference between the failed disks/failgroups. But the problem occurs if you have one failure (like CELLI03 diskgroup disappears) and after some time another failgroup fails (like CELLI07). The detail is that between the failures, the databases continued to run and change data in the disk. And when this occurs, and when your failgroup returns, there are differences.
Another point that is very important to understand is the time to recover the failure. If you have one disk/failgroup at ASM, the attributes disk_repair_time and failgroup_repair_time define the time that you have to repair your failure before the rebalance of data takes place. The first (disk_repair_time) is the time that you have to repair the disk in case of failure if your failgroup have more than one disk, just the failed is rebalanced. The second (failgroup_repair_time) is the time that you have to repair the failed failgroup (when it fails completely).
The interesting here is that between the moment of failure until the end of this clock you are susceptible to another failure. If it occurs (more failures that your mirror protection) you will lose the diskgroup. And another fact here it is that between the failures, your databases continue to run, so, if your return the first failed disk/failgroup, you need to sync it.
These “repair times” serve to provide to you time to fix/recover the failure and avoid the rebalance. Think about the architecture, usually the diskgroups with redundancy are big and protect big environments think in one Exadata, as an example, where each disk can have 14TB – and one cell can have until 12 of them), and do rebalance of this amount of data takes a lot of time. To avoid this, if your failed disk is replaced before this time, just sync with the block changed is needed.
A “default configuration” have these values:
SQL> select dg.name,a.value,a.name 2 from v$asm_diskgroup dg, v$asm_attribute a 3 where dg.group_number=a.group_number 4 and a.name like '%time' 5 / NAME VALUE NAME ---------------------------------------- --------------- ---------------------------------------- DATA 12.0h disk_repair_time DATA 24.0h failgroup_repair_time RECO 24.0h failgroup_repair_time RECO 12.0h disk_repair_time SYSTEMDG 24.0h failgroup_repair_time SYSTEMDG 12.0h disk_repair_time 6 rows selected. SQL>
But think in one scenario where more than one failure occurs, the first in CELLI01 at 08:00 am and the second in CELL0I6 at 10:00 am, now, from two hours, you have the new version of blocks. If you fix the failure (for CELL01) you don’t guarantee that you have everything in the last version and the normal mount will not work.
And it is here that mount restricted force for recovery enters. It allows you to resurrect the diskgroup and help you to restore fewer things. Think in the example before, if the failures occur at CELLI01 and CELL06, but your datafiles are in CELLI02 and CELLI07, you lose nothing. Or restore just some tablespaces and not all database. So, it is more gain than lose.
Mount restricted force for recovery
Here, I will simulate multiple failures for the disks (more than one) and show how you can use mount restricted force for recovery. Please be careful and follow all the steps correctly to avoid mistakes and to understand how to do and what is happening.
So, here I have DATA diskgroup, with normal redundancy and 7 (seven) failgroups. DBA19, DBB19, and DBC19 databases running.
So, at the first step, I will simulate a complete failure of CELLI03 failgroup. In my environment, to allow more control, I have one iSCSI target for each failgroup (this allows me to disconnect one by one if needed). The CELLI03 died:
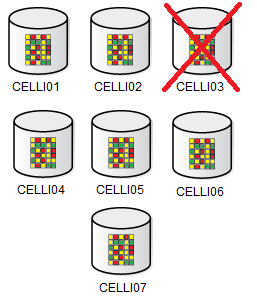
[root@asmrec ~]# iscsiadm -m session tcp: [11] 172.16.0.3:3260,1 iqn.2006-01.com.openfiler:tsn.d65b214fca9a (non-flash) --CELLI04 tcp: [14] 172.16.0.3:3260,1 iqn.2006-01.com.openfiler:tsn.637b3bbfa86d (non-flash) --CELLI07 tcp: [17] 172.16.0.3:3260,1 iqn.2006-01.com.openfiler:tsn.2f4cdb93107c (non-flash) --CELLI05 tcp: [2] 172.16.0.3:3260,1 iqn.2006-01.com.openfiler:tsn.bb66b92348a7 (non-flash) --CELLI03 tcp: [20] 172.16.0.3:3260,1 iqn.2006-01.com.openfiler:tsn.57c0a000e316 (non-flash) --(SYS) tcp: [23] 172.16.0.3:3260,1 iqn.2006-01.com.openfiler:tsn.89ef4420ea4d (non-flash) --CELLI06 tcp: [5] 172.16.0.3:3260,1 iqn.2006-01.com.openfiler:tsn.eff4683320e8 (non-flash) --CELLI01 tcp: [8] 172.16.0.3:3260,1 iqn.2006-01.com.openfiler:tsn.7d8f4c8f5012 (non-flash) --CELLI02 [root@asmrec ~]# [root@asmrec ~]# iscsiadm -m node -T iqn.2006-01.com.openfiler:tsn.bb66b92348a7 -p 172.16.0.3:3260 -u Logging out of session [sid: 2, target: iqn.2006-01.com.openfiler:tsn.bb66b92348a7, portal: 172.16.0.3,3260] Logout of [sid: 2, target: iqn.2006-01.com.openfiler:tsn.bb66b92348a7, portal: 172.16.0.3,3260] successful. [root@asmrec ~]#
And at ASM alertlog we can see:
2020-03-22T17:14:11.589115+01:00
NOTE: process _user8100_+asm1 (8100) initiating offline of disk 9.4042310133 (CELLI03) with mask 0x7e in group 1 (DATA) with client assisting
NOTE: checking PST: grp = 1
2020-03-22T17:14:11.589394+01:00
GMON checking disk modes for group 1 at 127 for pid 40, osid 8100
2020-03-22T17:14:11.589584+01:00
NOTE: checking PST for grp 1 done.
NOTE: initiating PST update: grp 1 (DATA), dsk = 9/0xf0f0c1f5, mask = 0x6a, op = clear mandatory
2020-03-22T17:14:11.589746+01:00
GMON updating disk modes for group 1 at 128 for pid 40, osid 8100
cluster guid (e4db41a22bd95fc6bf79d2e2c93360c7) generated for PST Hbeat for instance 1
WARNING: Write Failed. group:1 disk:9 AU:1 offset:4190208 size:4096
path:ORCL:CELLI03
incarnation:0xf0f0c1f5 synchronous result:'I/O error'
subsys:/opt/oracle/extapi/64/asm/orcl/1/libasm.so krq:0x7f9182f72210 bufp:0x7f9182f78000 osderr1:0x3 osderr2:0x2e
IO elapsed time: 0 usec Time waited on I/O: 0 usec
WARNING: found another non-responsive disk 9.4042310133 (CELLI03) that will be offlined
So, the failure occurred at 17:14. The full output from ASM alertlog can be found here at ASM-ALERTLOG-Output-Failure-CELLI03.txt
And we can see that disappeared (but not deleted or dropped) from ASM:
SQL> select NAME,FAILGROUP,LABEL,PATH from v$asm_disk order by FAILGROUP, label; NAME FAILGROUP LABEL PATH ---------------------------------------- ------------------------------ ------------------------------- ------------------------------------------------------------ CELLI01 CELLI01 CELLI01 ORCL:CELLI01 CELLI02 CELLI02 CELLI02 ORCL:CELLI02 CELLI03 CELLI03 CELLI04 CELLI04 CELLI04 ORCL:CELLI04 CELLI05 CELLI05 CELLI05 ORCL:CELLI05 CELLI06 CELLI06 CELLI06 ORCL:CELLI06 CELLI07 CELLI07 CELLI07 ORCL:CELLI07 RECI01 RECI01 RECI01 ORCL:RECI01 SYSTEMIDG01 SYSTEMIDG01 SYSI01 ORCL:SYSI01 9 rows selected. SQL>
At this point, ASM is starting to count the clock of 12hours (as defined in my repair attributes). The failgroup was not dropped and rebalance was not going on because ASM is optimistic that you will fix the issue in this period.
But after some time I had a second failure in the diskgroup:

Now at ASM alertlog you can see that diskgroup was dismounted (and several other messages). Bellow a cropped from the alertlog. The full output (and I think that deserve a look) it is here at ASM-ALERTLOG-Output-Failure-CELLI03-and-CELL01
2020-03-22T17:18:39.699555+01:00
WARNING: Write Failed. group:1 disk:1 AU:1 offset:4190208 size:4096
path:ORCL:CELLI01
incarnation:0xf0f0c1f3 asynchronous result:'I/O error'
subsys:/opt/oracle/extapi/64/asm/orcl/1/libasm.so krq:0x7f9182f833d0 bufp:0x7f91836ef000 osderr1:0x3 osderr2:0x2e
IO elapsed time: 0 usec Time waited on I/O: 0 usec
WARNING: Hbeat write to PST disk 1.4042310131 in group 1 failed. [2]
2020-03-22T17:18:39.704035+01:00
...
...
2020-03-22T17:18:39.746945+01:00
NOTE: cache closing disk 9 of grp 1: (not open) CELLI03
ERROR: disk 1 (CELLI01) in group 1 (DATA) cannot be offlined because all disks [1(CELLI01), 9(CELLI03)] with mirrored data would be offline.
2020-03-22T17:18:39.747462+01:00
ERROR: too many offline disks in PST (grp 1)
2020-03-22T17:18:39.759171+01:00
NOTE: cache dismounting (not clean) group 1/0xB48031B9 (DATA)
NOTE: messaging CKPT to quiesce pins Unix process pid: 12050, image: oracle@asmrec.oralocal (B001)
2020-03-22T17:18:39.761807+01:00
NOTE: halting all I/Os to diskgroup 1 (DATA)
2020-03-22T17:18:39.766289+01:00
NOTE: LGWR doing non-clean dismount of group 1 (DATA) thread 1
NOTE: LGWR sync ABA=23.3751 last written ABA 23.3751
...
...
2020-03-22T17:18:40.207406+01:00
SQL> alter diskgroup DATA dismount force /* ASM SERVER:3028300217 */
...
...
2020-03-22T17:18:40.841979+01:00
Errors in file /u01/app/grid/diag/asm/+asm/+ASM1/trace/+ASM1_rbal_8756.trc:
ORA-15130: diskgroup "DATA" is being dismounted
2020-03-22T17:18:40.853738+01:00
...
...
ERROR: disk 1 (CELLI01) in group 1 (DATA) cannot be offlined because all disks [1(CELLI01), 9(CELLI03)] with mirrored data would be offline.
2020-03-22T17:18:40.861939+01:00
ERROR: too many offline disks in PST (grp 1)
...
...
2020-03-22T17:18:43.214368+01:00
Errors in file /u01/app/grid/diag/asm/+asm/+ASM1/trace/+ASM1_rbal_8756.trc:
ORA-15130: diskgroup "DATA" is being dismounted
2020-03-22T17:18:43.214885+01:00
NOTE: client DBC19:DBC19:asmrec no longer has group 1 (DATA) mounted
2020-03-22T17:18:43.215492+01:00
NOTE: client DBB19:DBB19:asmrec no longer has group 1 (DATA) mounted
NOTE: cache deleting context for group DATA 1/0xb48031b9
...
...
2020-03-22T17:18:43.298551+01:00
SUCCESS: alter diskgroup DATA dismount force /* ASM SERVER:3028300217 */
SUCCESS: ASM-initiated MANDATORY DISMOUNT of group DATA
2020-03-22T17:18:43.352003+01:00
SQL> ALTER DISKGROUP DATA MOUNT /* asm agent *//* {0:1:9} */
2020-03-22T17:18:43.372816+01:00
NOTE: cache registered group DATA 1/0xB44031BF
NOTE: cache began mount (first) of group DATA 1/0xB44031BF
NOTE: Assigning number (1,8) to disk (ORCL:CELLI02)
NOTE: Assigning number (1,0) to disk (ORCL:CELLI04)
NOTE: Assigning number (1,11) to disk (ORCL:CELLI05)
NOTE: Assigning number (1,3) to disk (ORCL:CELLI06)
NOTE: Assigning number (1,2) to disk (ORCL:CELLI07)
2020-03-22T17:18:43.514642+01:00
cluster guid (e4db41a22bd95fc6bf79d2e2c93360c7) generated for PST Hbeat for instance 1
2020-03-22T17:18:46.089517+01:00
NOTE: detected and added orphaned client id 0x10010
NOTE: detected and added orphaned client id 0x1000e
So, the second failure occurred at 17:18 and lead to diskgroup force dismount. And you can see messages like “NOTE: cache dismounting (not clean)”, “ERROR: too many offline disks in PST (grp 1)”, and even “ERROR: disk 1 (CELLI01) in group 1 (DATA) cannot be offlined because all disks [1(CELLI01), 9(CELLI03)] with mirrored data would be offline”.
So, probably some data was lost. And even if you consider that between these 4 minutes data was changed in the databases, the mess is Big. If you want to see the alertlog from databases, check here at ASM-ALERTLOG-Output-From-Databases-Alertlog-at-Failure
And now we have this at ASM:
SQL> select NAME,FAILGROUP,LABEL,PATH from v$asm_disk order by FAILGROUP, label;
NAME FAILGROUP LABEL PATH
---------------------------------------- ------------------------------ ------------------------------- ------------------------------------------------------------
RECI01 RECI01 RECI01 ORCL:RECI01
SYSTEMIDG01 SYSTEMIDG01 SYSI01 ORCL:SYSI01
CELLI02 ORCL:CELLI02
CELLI04 ORCL:CELLI04
CELLI05 ORCL:CELLI05
CELLI06 ORCL:CELLI06
CELLI07 ORCL:CELLI07
7 rows selected.
SQL>
And if we try to mount we receive an error due to disk offline:
SQL> alter diskgroup data mount; alter diskgroup data mount * ERROR at line 1: ORA-15032: not all alterations performed ORA-15040: diskgroup is incomplete ORA-15042: ASM disk "9" is missing from group number "1" ORA-15042: ASM disk "1" is missing from group number "1" SQL>
Now is the key decision. If you have important data that worth the effort to try to recover you can continue. It is your decision and based on several details. Since the diskgroup is dismounted, the repair time is not counting, and you have days until recovery. Sometimes one day stopped is better than several days to recover all databases from the last backup.
Imagine that you can bring online the first failed failgroup (CELL03) that have 4 minutes of the difference of data:
[root@asmrec ~]# iscsiadm -m node -T iqn.2006-01.com.openfiler:tsn.bb66b92348a7 -p 172.16.0.3:3260 -l Logging in to [iface: default, target: iqn.2006-01.com.openfiler:tsn.bb66b92348a7, portal: 172.16.0.3,3260] (multiple) Login to [iface: default, target: iqn.2006-01.com.openfiler:tsn.bb66b92348a7, portal: 172.16.0.3,3260] successful. [root@asmrec ~]#
And if you try to mount it normally you will receive an error (output from alertlog at this try can be seen here at ASM-ALERTLOG-Output-Mout-With-One-Disk-Online)
SQL> alter diskgroup data mount; alter diskgroup data mount * ERROR at line 1: ORA-15032: not all alterations performed ORA-15017: diskgroup "DATA" cannot be mounted ORA-15066: offlining disk "1" in group "DATA" may result in a data loss SQL>
So, now we can try the mount restricted force for recovery:
SQL> alter diskgroup data mount restricted force for recovery; Diskgroup altered. SQL>
The alertlog from ASM (that you can full here at ASM-ALERTLOG-Output-Mout-Restricted-Force-For-Recovery) report messages related with the cache from diskgroup and disk that need to be checked. And now we are like this:
SQL> select NAME,FAILGROUP,LABEL,PATH from v$asm_disk order by FAILGROUP, label;
NAME FAILGROUP LABEL PATH
---------------------------------------- ------------------------------ ------------------------------- ------------------------------------------------------------
CELLI01 CELLI01
CELLI02 CELLI02 CELLI02 ORCL:CELLI02
CELLI03 CELLI03
CELLI04 CELLI04 CELLI04 ORCL:CELLI04
CELLI05 CELLI05 CELLI05 ORCL:CELLI05
CELLI06 CELLI06 CELLI06 ORCL:CELLI06
CELLI07 CELLI07 CELLI07 ORCL:CELLI07
RECI01 RECI01 RECI01 ORCL:RECI01
SYSTEMIDG01 SYSTEMIDG01 SYSI01 ORCL:SYSI01
CELLI03 ORCL:CELLI03
10 rows selected.
SQL>
The next step is to bring online the failgroup that came back:
SQL> alter diskgroup data online disks in failgroup CELLI03; Diskgroup altered. SQL>
Doing this ASM will resync this failgroup (using this block as the last version) and bring the cache of this disk online. At ASM alertlog you can see messages like (full output here at ASM-ALERTLOG-Output-Online-Restored-Failgroup):
2020-03-22T17:27:47.729003+01:00 SQL> alter diskgroup data online disks in failgroup CELLI03 2020-03-22T17:27:47.729551+01:00 NOTE: cache closing disk 1 of grp 1: (not open) CELLI01 2020-03-22T17:27:47.729640+01:00 NOTE: cache closing disk 9 of grp 1: (not open) CELLI03 2020-03-22T17:27:47.730398+01:00 NOTE: GroupBlock outside rolling migration privileged region NOTE: initiating resync of disk group 1 disks CELLI03 (9) NOTE: process _user6891_+asm1 (6891) initiating offline of disk 9.4042310248 (CELLI03) with mask 0x7e in group 1 (DATA) without client assisting 2020-03-22T17:27:47.737580+01:00 ... ... 2020-03-22T17:27:47.796524+01:00 NOTE: disk validation pending for 1 disk in group 1/0x1d7031d4 (DATA) NOTE: Found ORCL:CELLI03 for disk CELLI03 NOTE: completed disk validation for 1/0x1d7031d4 (DATA) 2020-03-22T17:27:47.935467+01:00 ... ... 2020-03-22T17:27:48.116572+01:00 NOTE: cache closing disk 1 of grp 1: (not open) CELLI01 NOTE: cache opening disk 9 of grp 1: CELLI03 label:CELLI03 2020-03-22T17:27:48.117158+01:00 SUCCESS: refreshed membership for 1/0x1d7031d4 (DATA) 2020-03-22T17:27:48.123545+01:00 NOTE: initiating PST update: grp 1 (DATA), dsk = 9/0x0, mask = 0x5d, op = assign mandatory ... ... 2020-03-22T17:27:48.142068+01:00 NOTE: PST update grp = 1 completed successfully 2020-03-22T17:27:48.143197+01:00 SUCCESS: alter diskgroup data online disks in failgroup CELLI03 2020-03-22T17:27:48.577277+01:00 NOTE: Attempting voting file refresh on diskgroup DATA NOTE: Refresh completed on diskgroup DATA. No voting file found. ... ... 2020-03-22T17:27:48.643277+01:00 NOTE: Starting resync using Staleness Registry and ATE scan for group 1 2020-03-22T17:27:48.696075+01:00 NOTE: Starting resync using Staleness Registry and ATE scan for group 1 NOTE: header on disk 9 advanced to format #2 using fcn 0.0 2020-03-22T17:27:49.725837+01:00 WARNING: Started Drop Disk Timeout for Disk 1 (CELLI01) in group 1 with a value 43200 2020-03-22T17:27:57.301042+01:00 ... 2020-03-22T17:27:59.687480+01:00 NOTE: cache closing disk 1 of grp 1: (not open) CELLI01 NOTE: reset timers for disk: 9 NOTE: completed online of disk group 1 disks CELLI03 (9) 2020-03-22T17:27:59.714674+01:00 ERROR: ORA-15421 thrown in ARBA for group number 1 2020-03-22T17:27:59.714805+01:00 Errors in file /u01/app/grid/diag/asm/+asm/+ASM1/trace/+ASM1_arba_8786.trc: ORA-15421: Rebalance is not supported when the disk group is mounted for recovery. 2020-03-22T17:27:59.715047+01:00 NOTE: stopping process ARB0 NOTE: stopping process ARBA 2020-03-22T17:28:00.652115+01:00 NOTE: rebalance interrupted for group 1/0x1d7031d4 (DATA)
And not we have at ASM:
SQL> select NAME,FAILGROUP,LABEL,PATH from v$asm_disk order by FAILGROUP, label; NAME FAILGROUP LABEL PATH ---------------------------------------- ------------------------------ ------------------------------- ------------------------------------------------------------ CELLI01 CELLI01 CELLI02 CELLI02 CELLI02 ORCL:CELLI02 CELLI03 CELLI03 CELLI03 ORCL:CELLI03 CELLI04 CELLI04 CELLI04 ORCL:CELLI04 CELLI05 CELLI05 CELLI05 ORCL:CELLI05 CELLI06 CELLI06 CELLI06 ORCL:CELLI06 CELLI07 CELLI07 CELLI07 ORCL:CELLI07 RECI01 RECI01 RECI01 ORCL:RECI01 SYSTEMIDG01 SYSTEMIDG01 SYSI01 ORCL:SYSI01 9 rows selected. SQL>
And rebalance not continue because is not allowed when diskgroup is in restrict mode:
SQL> select * from gv$asm_operation;
INST_ID GROUP_NUMBER OPERA PASS STAT POWER ACTUAL SOFAR EST_WORK EST_RATE EST_MINUTES ERROR_CODE CON_ID
---------- ------------ ----- --------- ---- ---------- ---------- ---------- ---------- ---------- ----------- -------------------------------------------- ----------
1 1 REBAL COMPACT WAIT 1 0
1 1 REBAL REBALANCE ERRS 1 ORA-15421 0
1 1 REBAL REBUILD WAIT 1 0
1 1 REBAL RESYNC WAIT 1 0
SQL>
But since the failgroup become online “in force way”, the old cache (from CELL01) need to be clean. And since it is not the last version, maybe some files were corrupted. To check this, you can look the *arb* process trace files at ASM trace directory:
root@asmrec trace]# ls -lFhtr *arb* ... ... -rw-r----- 1 grid oinstall 6.4K Mar 22 17:10 +ASM1_arb0_3210.trm -rw-r----- 1 grid oinstall 44K Mar 22 17:10 +ASM1_arb0_3210.trc -rw-r----- 1 grid oinstall 984 Mar 22 17:27 +ASM1_arb0_8788.trm -rw-r----- 1 grid oinstall 2.1K Mar 22 17:27 +ASM1_arb0_8788.trc -rw-r----- 1 grid oinstall 882 Mar 22 17:27 +ASM1_arba_8786.trm -rw-r----- 1 grid oinstall 1.2K Mar 22 17:27 +ASM1_arba_8786.trc [root@asmrec trace]#
And looking from one of the last, we can see that some extend (that does not exist, the recovered failgroup, or the cache is not the last one) was filled with dummy (BADFDA7A) data:
[root@asmrec trace]# cat +ASM1_arb0_8788.trc Trace file /u01/app/grid/diag/asm/+asm/+ASM1/trace/+ASM1_arb0_8788.trc Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.6.0.0.0 Build label: RDBMS_19.3.0.0.0DBRU_LINUX.X64_190417 ORACLE_HOME: /u01/app/19.0.0.0/grid System name: Linux Node name: asmrec.oralocal Release: 4.14.35-1902.10.8.el7uek.x86_64 Version: #2 SMP Thu Feb 6 11:02:28 PST 2020 Machine: x86_64 Instance name: +ASM1 Redo thread mounted by this instance: 0 <none> Oracle process number: 40 Unix process pid: 8788, image: oracle@asmrec.oralocal (ARB0) *** 2020-03-22T17:27:59.044949+01:00 *** SESSION ID:(402.55837) 2020-03-22T17:27:59.044969+01:00 *** CLIENT ID:() 2020-03-22T17:27:59.044975+01:00 *** SERVICE NAME:() 2020-03-22T17:27:59.044980+01:00 *** MODULE NAME:() 2020-03-22T17:27:59.044985+01:00 *** ACTION NAME:() 2020-03-22T17:27:59.044989+01:00 *** CLIENT DRIVER:() 2020-03-22T17:27:59.044994+01:00 WARNING: group 1, file 266, extent 22: filling extent with BADFDA7A during recovery WARNING: group 1, file 266, extent 22: filling extent with BADFDA7A during recovery WARNING: group 1, file 266, extent 22: filling extent with BADFDA7A during recovery WARNING: group 1, file 266, extent 22: filling extent with BADFDA7A during recovery WARNING: group 1, file 258, extent 7: filling extent with BADFDA7A during recovery WARNING: group 1, file 258, extent 7: filling extent with BADFDA7A during recovery WARNING: group 1, file 258, extent 7: filling extent with BADFDA7A during recovery WARNING: group 1, file 258, extent 7: filling extent with BADFDA7A during recovery *** 2020-03-22T17:27:59.680119+01:00 NOTE: initiating PST update: grp 1 (DATA), dsk = 9/0x0, mask = 0x7f, op = assign mandatory kfdp_updateDsk(): callcnt 195 grp 1 PST verChk -0: req, id=266369333, grp=1, requested=91 at 03/22/2020 17:27:59 NOTE: PST update grp = 1 completed successfully NOTE: kfdsFilter_freeDskSrSlice for Filter 0x7fbaf6238d38 NOTE: kfdsFilter_clearDskSlice for Filter 0x7fbaf6238d38 (all:TRUE) NOTE: completed online of disk group 1 disks CELLI03 (9) [root@asmrec trace]#
And as you can imagine, this will lead to files that need to be restored from backup. But look that just some data, not everything. Remember at the beginning of the post that this depends on how your data is distributed inside of ASM failgroups. If you have luck, you have just a few data impacted. This depends on a lot of factors, as the time that was offline, the size of the failgroup, the activity of your databases, and many others. But, the gains can be good and mad it worth the effort.
After that, we can normally dismount the diskgroup:
SQL> alter diskgroup data dismount; Diskgroup altered. SQL>
And mount it again:
SQL> alter diskgroup data mount; Diskgroup altered. SQL>
Since now the diskgroup is mounted in a clean way, you can continue with the rebalance:
SQL> select * from gv$asm_operation;
INST_ID GROUP_NUMBER OPERA PASS STAT POWER ACTUAL SOFAR EST_WORK EST_RATE EST_MINUTES ERROR_CODE CON_ID
---------- ------------ ----- --------- ---- ---------- ---------- ---------- ---------- ---------- ----------- -------------------------------------------- ----------
1 1 REBAL COMPACT WAIT 1 0
1 1 REBAL REBALANCE ERRS 1 ORA-15421 0
1 1 REBAL REBUILD WAIT 1 0
1 1 REBAL RESYNC WAIT 1 0
SQL> alter diskgroup DATA rebalance;
Diskgroup altered.
SQL>
The state at ASM side it is:
SQL> select NAME,FAILGROUP,LABEL,PATH from v$asm_disk order by FAILGROUP, label; NAME FAILGROUP LABEL PATH ---------------------------------------- ------------------------------ ------------------------------- ------------------------------------------------------------ CELLI01 CELLI01 CELLI02 CELLI02 CELLI02 ORCL:CELLI02 CELLI03 CELLI03 CELLI03 ORCL:CELLI03 CELLI04 CELLI04 CELLI04 ORCL:CELLI04 CELLI05 CELLI05 CELLI05 ORCL:CELLI05 CELLI06 CELLI06 CELLI06 ORCL:CELLI06 CELLI07 CELLI07 CELLI07 ORCL:CELLI07 RECI01 RECI01 RECI01 ORCL:RECI01 SYSTEMIDG01 SYSTEMIDG01 SYSI01 ORCL:SYSI01 9 rows selected. SQL>
As you can see, the CELL01 was not removed yet (I will talk about it later). But the activities can continue, databases can be checked.
Database side
At the database side, we need to check what we lost and need to recover. Since I am using cluster the GI tried to start it (and as you can see two became up):
[oracle@asmrec ~]$ ps -ef |grep smon root 8254 1 2 13:53 ? 00:04:40 /u01/app/19.0.0.0/grid/bin/osysmond.bin grid 8750 1 0 13:54 ? 00:00:00 asm_smon_+ASM1 oracle 11589 1 0 17:31 ? 00:00:00 ora_smon_DBB19 oracle 11751 1 0 17:31 ? 00:00:00 ora_smon_DBA19 oracle 18817 29146 0 17:44 pts/9 00:00:00 grep --color=auto smon [oracle@asmrec ~]$
DBA19
The firs that I checked was DBA19C, I used rman to VALIDATE DATABASE:
[oracle@asmrec ~]$ rman target /
Recovery Manager: Release 19.0.0.0.0 - Production on Sun Mar 22 17:45:21 2020
Version 19.6.0.0.0
Copyright (c) 1982, 2019, Oracle and/or its affiliates. All rights reserved.
connected to target database: DBA19 (DBID=828667324)
RMAN> validate database;
Starting validate at 22-MAR-20
using target database control file instead of recovery catalog
allocated channel: ORA_DISK_1
channel ORA_DISK_1: SID=260 device type=DISK
channel ORA_DISK_1: starting validation of datafile
channel ORA_DISK_1: specifying datafile(s) for validation
input datafile file number=00001 name=+DATA/DBA19/DATAFILE/system.256.1035153873
input datafile file number=00004 name=+DATA/DBA19/DATAFILE/undotbs1.258.1035153973
input datafile file number=00003 name=+DATA/DBA19/DATAFILE/sysaux.257.1035153927
input datafile file number=00007 name=+DATA/DBA19/DATAFILE/users.259.1035153975
channel ORA_DISK_1: validation complete, elapsed time: 00:03:45
List of Datafiles
=================
File Status Marked Corrupt Empty Blocks Blocks Examined High SCN
---- ------ -------------- ------------ --------------- ----------
1 OK 0 17722 117766 5042446
File Name: +DATA/DBA19/DATAFILE/system.256.1035153873
Block Type Blocks Failing Blocks Processed
---------- -------------- ----------------
Data 0 79105
Index 0 13210
Other 0 7723
File Status Marked Corrupt Empty Blocks Blocks Examined High SCN
---- ------ -------------- ------------ --------------- ----------
3 OK 0 19445 67862 5042695
File Name: +DATA/DBA19/DATAFILE/sysaux.257.1035153927
Block Type Blocks Failing Blocks Processed
---------- -------------- ----------------
Data 0 7988
Index 0 5531
Other 0 34876
File Status Marked Corrupt Empty Blocks Blocks Examined High SCN
---- ------ -------------- ------------ --------------- ----------
4 FAILED 1 49 83247 5042695
File Name: +DATA/DBA19/DATAFILE/undotbs1.258.1035153973
Block Type Blocks Failing Blocks Processed
---------- -------------- ----------------
Data 0 0
Index 0 0
Other 511 83151
File Status Marked Corrupt Empty Blocks Blocks Examined High SCN
---- ------ -------------- ------------ --------------- ----------
7 OK 0 93 641 4941613
File Name: +DATA/DBA19/DATAFILE/users.259.1035153975
Block Type Blocks Failing Blocks Processed
---------- -------------- ----------------
Data 0 65
Index 0 15
Other 0 467
validate found one or more corrupt blocks
See trace file /u01/app/oracle/diag/rdbms/dba19/DBA19/trace/DBA19_ora_19219.trc for details
channel ORA_DISK_1: starting validation of datafile
channel ORA_DISK_1: specifying datafile(s) for validation
including current control file for validation
including current SPFILE in backup set
channel ORA_DISK_1: validation complete, elapsed time: 00:00:01
List of Control File and SPFILE
===============================
File Type Status Blocks Failing Blocks Examined
------------ ------ -------------- ---------------
SPFILE OK 0 2
Control File OK 0 646
Finished validate at 22-MAR-20
RMAN> shutdown abort;
Oracle instance shut down
RMAN> startup mount;
connected to target database (not started)
Oracle instance started
database mounted
Total System Global Area 1610610776 bytes
Fixed Size 8910936 bytes
Variable Size 859832320 bytes
Database Buffers 734003200 bytes
Redo Buffers 7864320 bytes
RMAN> run{
2> restore datafile 4;
3> recover datafile 4;
4> }
Starting restore at 22-MAR-20
allocated channel: ORA_DISK_1
channel ORA_DISK_1: SID=249 device type=DISK
channel ORA_DISK_1: starting datafile backup set restore
channel ORA_DISK_1: specifying datafile(s) to restore from backup set
channel ORA_DISK_1: restoring datafile 00004 to +DATA/DBA19/DATAFILE/undotbs1.258.1035153973
channel ORA_DISK_1: reading from backup piece /tmp/9puro5qr_1_1
channel ORA_DISK_1: piece handle=/tmp/9puro5qr_1_1 tag=BKP-DB-INC0
channel ORA_DISK_1: restored backup piece 1
channel ORA_DISK_1: restore complete, elapsed time: 00:00:45
Finished restore at 22-MAR-20
Starting recover at 22-MAR-20
using channel ORA_DISK_1
starting media recovery
media recovery complete, elapsed time: 00:00:02
Finished recover at 22-MAR-20
RMAN> alter database open;
Statement processed
RMAN> exit
Recovery Manager complete.
[oracle@asmrec ~]$
As you can see, the datafile 4 FAILED and needs to be recovered. Luckily, the redo was not affected too and the open was OK. Since it was the UNDO, I made abort (because the immediate can take an eternity, and even since undo was down, nothing was happening inside of the database).
But as you saw, just one datafile was corrupted. Of course that with big databases and big failgroup, more files will be corrupted. But it is a shot that can worth it.
DBB19
The second was DBB19 and I used the same approach, VALIDATE DATABASE:
[oracle@asmrec ~]$ export ORACLE_SID=DBB19 [oracle@asmrec ~]$ [oracle@asmrec ~]$ rman target / Recovery Manager: Release 19.0.0.0.0 - Production on Sun Mar 22 17:55:20 2020 Version 19.6.0.0.0 Copyright (c) 1982, 2019, Oracle and/or its affiliates. All rights reserved. PL/SQL package SYS.DBMS_BACKUP_RESTORE version 19.03.00.00 in TARGET database is not current PL/SQL package SYS.DBMS_RCVMAN version 19.03.00.00 in TARGET database is not current connected to target database: DBB19 (DBID=1336872427) RMAN> validate database; Starting validate at 22-MAR-20 using target database control file instead of recovery catalog allocated channel: ORA_DISK_1 channel ORA_DISK_1: SID=374 device type=DISK channel ORA_DISK_1: starting validation of datafile channel ORA_DISK_1: specifying datafile(s) for validation input datafile file number=00001 name=+DATA/DBB19/DATAFILE/system.261.1035154051 input datafile file number=00003 name=+DATA/DBB19/DATAFILE/sysaux.265.1035154177 input datafile file number=00004 name=+DATA/DBB19/DATAFILE/undotbs1.267.1035154235 input datafile file number=00007 name=+DATA/DBB19/DATAFILE/users.268.1035154241 channel ORA_DISK_1: validation complete, elapsed time: 00:00:35 List of Datafiles ================= File Status Marked Corrupt Empty Blocks Blocks Examined High SCN ---- ------ -------------- ------------ --------------- ---------- 1 OK 0 16763 116487 3861452 File Name: +DATA/DBB19/DATAFILE/system.261.1035154051 Block Type Blocks Failing Blocks Processed ---------- -------------- ---------------- Data 0 78871 Index 0 13010 Other 0 7836 File Status Marked Corrupt Empty Blocks Blocks Examined High SCN ---- ------ -------------- ------------ --------------- ---------- 3 OK 0 19307 62758 3861452 File Name: +DATA/DBB19/DATAFILE/sysaux.265.1035154177 Block Type Blocks Failing Blocks Processed ---------- -------------- ---------------- Data 0 7459 Index 0 5158 Other 0 30796 File Status Marked Corrupt Empty Blocks Blocks Examined High SCN ---- ------ -------------- ------------ --------------- ---------- 4 OK 0 1 35847 3652497 File Name: +DATA/DBB19/DATAFILE/undotbs1.267.1035154235 Block Type Blocks Failing Blocks Processed ---------- -------------- ---------------- Data 0 0 Index 0 0 Other 0 35839 File Status Marked Corrupt Empty Blocks Blocks Examined High SCN ---- ------ -------------- ------------ --------------- ---------- 7 OK 0 85 641 3759202 File Name: +DATA/DBB19/DATAFILE/users.268.1035154241 Block Type Blocks Failing Blocks Processed ---------- -------------- ---------------- Data 0 70 Index 0 15 Other 0 470 channel ORA_DISK_1: starting validation of datafile channel ORA_DISK_1: specifying datafile(s) for validation including current control file for validation including current SPFILE in backup set channel ORA_DISK_1: validation complete, elapsed time: 00:00:01 List of Control File and SPFILE =============================== File Type Status Blocks Failing Blocks Examined ------------ ------ -------------- --------------- SPFILE OK 0 2 Control File OK 0 646 Finished validate at 22-MAR-20 RMAN> VALIDATE CHECK LOGICAL DATABASE; Starting validate at 22-MAR-20 using channel ORA_DISK_1 channel ORA_DISK_1: starting validation of datafile channel ORA_DISK_1: specifying datafile(s) for validation input datafile file number=00001 name=+DATA/DBB19/DATAFILE/system.261.1035154051 input datafile file number=00003 name=+DATA/DBB19/DATAFILE/sysaux.265.1035154177 input datafile file number=00004 name=+DATA/DBB19/DATAFILE/undotbs1.267.1035154235 input datafile file number=00007 name=+DATA/DBB19/DATAFILE/users.268.1035154241 channel ORA_DISK_1: validation complete, elapsed time: 00:00:35 List of Datafiles ================= File Status Marked Corrupt Empty Blocks Blocks Examined High SCN ---- ------ -------------- ------------ --------------- ---------- 1 OK 0 16763 116487 3861452 File Name: +DATA/DBB19/DATAFILE/system.261.1035154051 Block Type Blocks Failing Blocks Processed ---------- -------------- ---------------- Data 0 78871 Index 0 13010 Other 0 7836 File Status Marked Corrupt Empty Blocks Blocks Examined High SCN ---- ------ -------------- ------------ --------------- ---------- 3 OK 0 19307 62758 3861452 File Name: +DATA/DBB19/DATAFILE/sysaux.265.1035154177 Block Type Blocks Failing Blocks Processed ---------- -------------- ---------------- Data 0 7459 Index 0 5158 Other 0 30796 File Status Marked Corrupt Empty Blocks Blocks Examined High SCN ---- ------ -------------- ------------ --------------- ---------- 4 OK 0 1 35847 3652497 File Name: +DATA/DBB19/DATAFILE/undotbs1.267.1035154235 Block Type Blocks Failing Blocks Processed ---------- -------------- ---------------- Data 0 0 Index 0 0 Other 0 35839 File Status Marked Corrupt Empty Blocks Blocks Examined High SCN ---- ------ -------------- ------------ --------------- ---------- 7 OK 0 85 641 3759202 File Name: +DATA/DBB19/DATAFILE/users.268.1035154241 Block Type Blocks Failing Blocks Processed ---------- -------------- ---------------- Data 0 70 Index 0 15 Other 0 470 channel ORA_DISK_1: starting validation of datafile channel ORA_DISK_1: specifying datafile(s) for validation including current control file for validation including current SPFILE in backup set channel ORA_DISK_1: validation complete, elapsed time: 00:00:01 List of Control File and SPFILE =============================== File Type Status Blocks Failing Blocks Examined ------------ ------ -------------- --------------- SPFILE OK 0 2 Control File OK 0 646 Finished validate at 22-MAR-20 RMAN> exit Recovery Manager complete. [oracle@asmrec ~]$
As you saw, no failures for DBB19. I still checked logically the database with VALIDATE CHECK LOGICAL DATABASE because since the validate returned no failed files, I wanted to check logically the blocks.
DBC19
Same for the last database, but now, datafile 3 failed:
[oracle@asmrec ~]$ export ORACLE_SID=DBC19
[oracle@asmrec ~]$ rman target /
Recovery Manager: Release 19.0.0.0.0 - Production on Sun Mar 22 18:01:33 2020
Version 19.6.0.0.0
Copyright (c) 1982, 2019, Oracle and/or its affiliates. All rights reserved.
connected to target database (not started)
RMAN> startup mount;
Oracle instance started
database mounted
Total System Global Area 1610610776 bytes
Fixed Size 8910936 bytes
Variable Size 864026624 bytes
Database Buffers 729808896 bytes
Redo Buffers 7864320 bytes
RMAN> validate database;
Starting validate at 22-MAR-20
using target database control file instead of recovery catalog
allocated channel: ORA_DISK_1
channel ORA_DISK_1: SID=134 device type=DISK
channel ORA_DISK_1: starting validation of datafile
channel ORA_DISK_1: specifying datafile(s) for validation
input datafile file number=00001 name=+DATA/DBC19/DATAFILE/system.262.1035154053
input datafile file number=00004 name=+DATA/DBC19/DATAFILE/undotbs1.270.1035154249
input datafile file number=00003 name=+DATA/DBC19/DATAFILE/sysaux.266.1035154181
input datafile file number=00007 name=+DATA/DBC19/DATAFILE/users.271.1035154253
channel ORA_DISK_1: validation complete, elapsed time: 00:03:15
List of Datafiles
=================
File Status Marked Corrupt Empty Blocks Blocks Examined High SCN
---- ------ -------------- ------------ --------------- ----------
1 OK 0 17777 117764 4188744
File Name: +DATA/DBC19/DATAFILE/system.262.1035154053
Block Type Blocks Failing Blocks Processed
---------- -------------- ----------------
Data 0 79161
Index 0 13182
Other 0 7640
File Status Marked Corrupt Empty Blocks Blocks Examined High SCN
---- ------ -------------- ------------ --------------- ----------
3 FAILED 1 19272 66585 4289434
File Name: +DATA/DBC19/DATAFILE/sysaux.266.1035154181
Block Type Blocks Failing Blocks Processed
---------- -------------- ----------------
Data 0 7311
Index 0 4878
Other 511 35099
File Status Marked Corrupt Empty Blocks Blocks Examined High SCN
---- ------ -------------- ------------ --------------- ----------
4 OK 0 1 84522 4188748
File Name: +DATA/DBC19/DATAFILE/undotbs1.270.1035154249
Block Type Blocks Failing Blocks Processed
---------- -------------- ----------------
Data 0 0
Index 0 0
Other 0 84479
File Status Marked Corrupt Empty Blocks Blocks Examined High SCN
---- ------ -------------- ------------ --------------- ----------
7 OK 0 93 641 3717377
File Name: +DATA/DBC19/DATAFILE/users.271.1035154253
Block Type Blocks Failing Blocks Processed
---------- -------------- ----------------
Data 0 65
Index 0 15
Other 0 467
validate found one or more corrupt blocks
See trace file /u01/app/oracle/diag/rdbms/dbc19/DBC19/trace/DBC19_ora_22091.trc for details
channel ORA_DISK_1: starting validation of datafile
channel ORA_DISK_1: specifying datafile(s) for validation
including current control file for validation
including current SPFILE in backup set
channel ORA_DISK_1: validation complete, elapsed time: 00:00:01
List of Control File and SPFILE
===============================
File Type Status Blocks Failing Blocks Examined
------------ ------ -------------- ---------------
SPFILE OK 0 2
Control File OK 0 646
Finished validate at 22-MAR-20
RMAN> run{
2> restore datafile 3;
3> recover datafile 3;
4> }
Starting restore at 22-MAR-20
using channel ORA_DISK_1
channel ORA_DISK_1: starting datafile backup set restore
channel ORA_DISK_1: specifying datafile(s) to restore from backup set
channel ORA_DISK_1: restoring datafile 00003 to +DATA/DBC19/DATAFILE/sysaux.266.1035154181
channel ORA_DISK_1: reading from backup piece /tmp/0buro5rh_1_1
channel ORA_DISK_1: piece handle=/tmp/0buro5rh_1_1 tag=BKP-DB-INC0
channel ORA_DISK_1: restored backup piece 1
channel ORA_DISK_1: restore complete, elapsed time: 00:00:45
Finished restore at 22-MAR-20
Starting recover at 22-MAR-20
using channel ORA_DISK_1
starting media recovery
archived log for thread 1 with sequence 25 is already on disk as file +RECO/DBC19/ARCHIVELOG/2020_03_22/thread_1_seq_25.323.1035737103
archived log for thread 1 with sequence 26 is already on disk as file +RECO/DBC19/ARCHIVELOG/2020_03_22/thread_1_seq_26.329.1035739907
archived log for thread 1 with sequence 27 is already on disk as file +RECO/DBC19/ARCHIVELOG/2020_03_22/thread_1_seq_27.332.1035741283
archived log file name=+RECO/DBC19/ARCHIVELOG/2020_03_22/thread_1_seq_25.323.1035737103 thread=1 sequence=25
media recovery complete, elapsed time: 00:00:03
Finished recover at 22-MAR-20
RMAN> alter database open;
Statement processed
RMAN> exit
Recovery Manager complete.
[oracle@asmrec ~]$
Dropping failgroup
If the fix for the remaining failgroup took a lot, it will be dropped automatically. But we can do this manually with force (look that without force it fails):
SQL> ALTER DISKGROUP data DROP DISKS IN FAILGROUP CELLI01; ALTER DISKGROUP data DROP DISKS IN FAILGROUP CELLI01 * ERROR at line 1: ORA-15032: not all alterations performed ORA-15084: ASM disk "CELLI01" is offline and cannot be dropped. SQL> SQL> ALTER DISKGROUP data DROP DISKS IN FAILGROUP CELLI01 FORCE; Diskgroup altered. SQL>
And after the rebalance finish, all disk will be removed:
SQL> select NAME,FAILGROUP,LABEL,PATH from v$asm_disk order by FAILGROUP, label;
NAME FAILGROUP LABEL PATH
---------------------------------------- ------------------------------ ------------------------------- ------------------------------------------------------------
_DROPPED_0001_DATA CELLI01
CELLI02 CELLI02 CELLI02 ORCL:CELLI02
CELLI03 CELLI03 CELLI03 ORCL:CELLI03
CELLI04 CELLI04 CELLI04 ORCL:CELLI04
CELLI05 CELLI05 CELLI05 ORCL:CELLI05
CELLI06 CELLI06 CELLI06 ORCL:CELLI06
CELLI07 CELLI07 CELLI07 ORCL:CELLI07
RECI01 RECI01 RECI01 ORCL:RECI01
SYSTEMIDG01 SYSTEMIDG01 SYSI01 ORCL:SYSI01
9 rows selected.
SQL> select * from gv$asm_operation;
INST_ID GROUP_NUMBER OPERA PASS STAT POWER ACTUAL SOFAR EST_WORK EST_RATE EST_MINUTES ERROR_CODE CON_ID
---------- ------------ ----- --------- ---- ---------- ---------- ---------- ---------- ---------- ----------- -------------------------------------------- ----------
1 1 REBAL COMPACT WAIT 1 1 0 0 0 0 0
1 1 REBAL REBALANCE WAIT 1 1 0 0 0 0 0
1 1 REBAL REBUILD RUN 1 1 292 642 666 0 0
1 1 REBAL RESYNC DONE 1 1 0 0 0 0 0
SQL> select * from gv$asm_operation;
no rows selected
SQL> select NAME,FAILGROUP,LABEL,PATH from v$asm_disk order by FAILGROUP, label;
NAME FAILGROUP LABEL PATH
---------------------------------------- ------------------------------ ------------------------------- ------------------------------------------------------------
CELLI02 CELLI02 CELLI02 ORCL:CELLI02
CELLI03 CELLI03 CELLI03 ORCL:CELLI03
CELLI04 CELLI04 CELLI04 ORCL:CELLI04
CELLI05 CELLI05 CELLI05 ORCL:CELLI05
CELLI06 CELLI06 CELLI06 ORCL:CELLI06
CELLI07 CELLI07 CELLI07 ORCL:CELLI07
RECI01 RECI01 RECI01 ORCL:RECI01
SYSTEMIDG01 SYSTEMIDG01 SYSI01 ORCL:SYSI01
8 rows selected.
SQL>
The steps for MOUNT RESTRICTED FORCE FOR RECOVERY
To resume, the steps needed are (in order):
- Put online the failed disk/failgroup
- Execute alter diskgroup <DG> mount restricted force for recovery
- Brink online the failgroup with alter diskgroup data online disks in failgroup <FG>
- Clean dismount DG alter diskgroup <DG> dismount
- Clean mount alter diskgroup <DG> mount
- Check databases for failures and recover it
Undocumented feature
So, the question is, why it is undocumented? I don’t have the answer but can figure out some points. For me, the most important is that is not a full, clean return. You need to restore and recover from the backup. Maybe you will lose a lot of data.
Of course that here in this example is a controlled scenario, I have just a few databases and my failgroup have just one disk inside. In real life, the problem will be worst. More diskgroups can be affected, as RECO/REDO/FRA. And probably you lost some redologs and archivelogs too and you can’t do a clean recovery. Or even need to recover OCR and Votedisk from the cluster.
This is the point for correct architecture design, if you need more protection at ASM side, you can use HIGH redundancy to survive at least two failures without interruption. This is the reason that SYSTEMDG (or OCR/Vote disk) is put high redundancy diskgroup at Exadata.
Outages and failures can occur in different layers of your environment. But storage/disk failures are catastrophic for databases because they can lead data corruption and you need to use backups to recover it. They can occur in any environment, from Storage until Exadata. I had one in an old Exadata V2 in 2016, used just for DEV databases, that crashed two storage cells (with one hour of difference) and needed to use this procedure to save some files and reduce the downtime avoiding to restore everything (more than 10TB).
So, it is good to know this kind of a procedure because can save time. But it is your decision to use it or no, check if worth or no.
Some references that you can check:
- Recover from diskgroup failure using the 12.1.0.2 “mount restricted force for recovery” feature – An Example (Doc ID 1968642.1)
- How to change the DISK_REPAIR_TIME timer after disk goes offline from failgroup (Doc ID 1404123.1)
- The ASM Priority Rebalance feature – An Example (Doc ID 1968607.1)
Disclaimer: “The postings on this site are my own and don’t necessarily represent my actual employer positions, strategies or opinions. The information here was edited to be useful for general purpose, specific data and identifications were removed to allow reach the generic audience and to be useful for the community. Post protected by copyright.”
Pingback: ZDLRA + MAA, Protection for Silver Architecture | Fernando Simon