The MAA defined Silver architecture for database environments that use (or need) high availability to survive for outages. The idea is having more than one single instance running, and to do that, it relies on Oracle Clusterware and Engineered Systems to mitigate the single point of failure. But is not just a database that gains with this, the Silver architecture is the first step to have application continuity. And again, ZDLRA is there since the beginning.
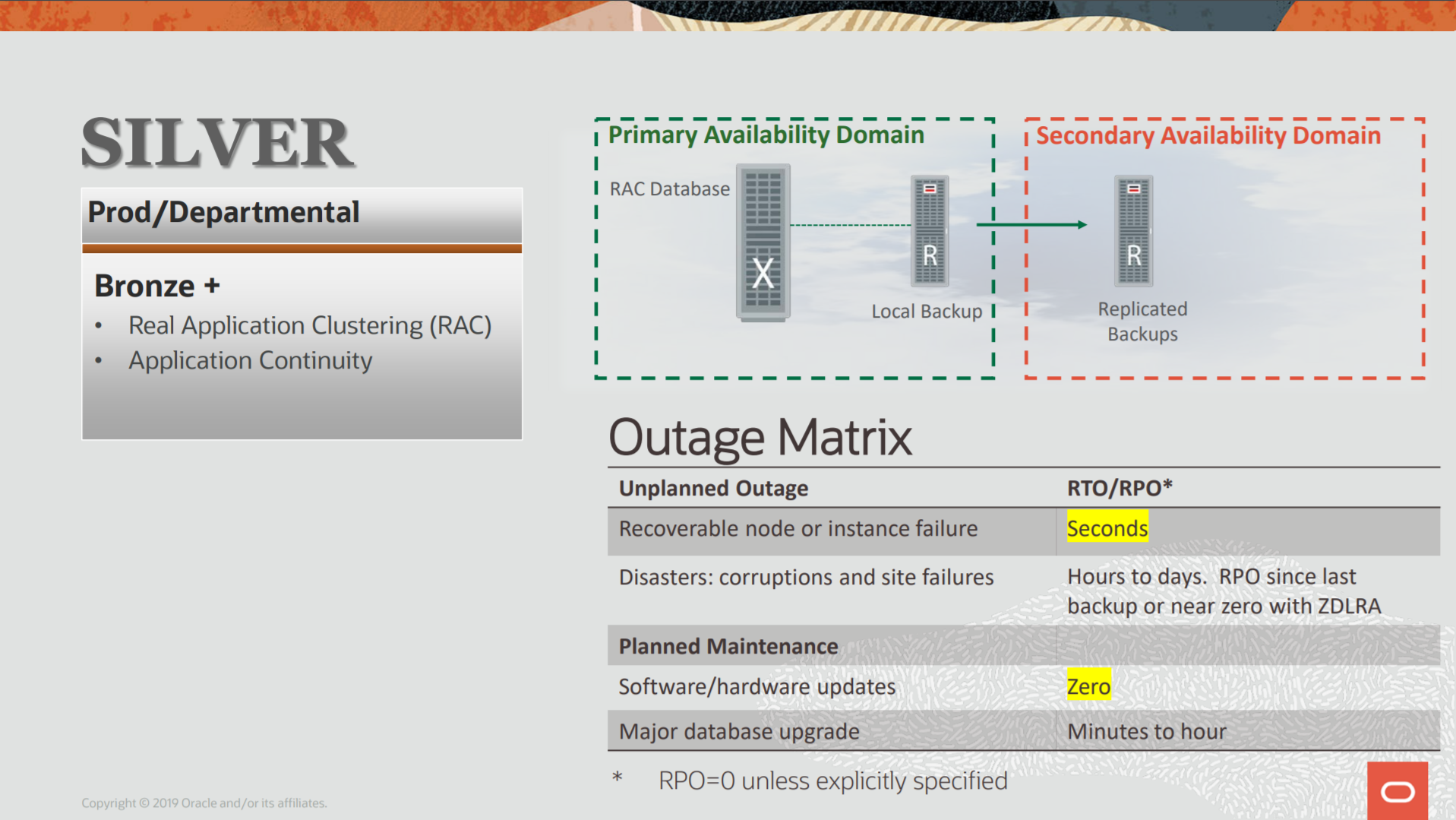 As you can see above, the Silver by MAA blueprints improves compared with Bronze architecture that I spoke at the last post. But the basic points are there: RPO and RTO. They continue to base rule here. And the goals are the same: Data Availability, Data Protection, Performance (no impact), Cost (lower cost), and Risk (reduce). More technical details here at the MAA Overview doc.
As you can see above, the Silver by MAA blueprints improves compared with Bronze architecture that I spoke at the last post. But the basic points are there: RPO and RTO. They continue to base rule here. And the goals are the same: Data Availability, Data Protection, Performance (no impact), Cost (lower cost), and Risk (reduce). More technical details here at the MAA Overview doc.
Silver Architecture
To improve the continuity the architecture relies on Oracle Clusterware to deliver the High Availability (HA), allowing your application to continue to run in case of failed node instance or even HW error from the database server. But is more than just have one more instance running (I will not explain all features in detail here, they are beyond the post scope), I will highlight some key details that can be used and are there to protect the database and we not notice.
Oracle Clusterware
As already wrote here, the point for Oracle Clusterware is to provide the basis for HA but is more than this, more than just RAC and ASM. It protects your from split brains, node eviction controls, servers, and services outages as an example.
Using workload management (Policy-management, or Administrator-Management) is possible to define how to respond in case of a node outage. Even a single instance can be failed over to another node and the database continues to operate with less impact.
So, the RTO is reduced because in case of failure the database operation resumes quickly using another node.
ASM
When you use RAC you need to have (at least) a shared filesystem, but for sure that ASM is the best option. The important detail at ASM is that you can bypass disk failures using mirroring and you can, at least, survive over a disk failure without an outage. Even with HIGH redundancy is possible to survive (with some lucky) to a double disk failure (of course that with some possible data loss). I already explained how to use the MOUNT RESTRICTED FORCE FOR RECOVERY in the previous post. And more than this, think that for maintenance/scalability you can add resources for one diskgroup (add more disks) without need to stop the databases.
The goal for ASM is simple, provide a better base environment to runs your database even in case of disk failure. If you compare this with the Bronze architecture you can see the improvement for the general environment.
Oracle RAC
First, Oracle RAC is not disaster recovery, is High Availability (read this old doc for reference). Is the capacity to survive one node outage and have continuous service/database for planned and unplanned outages. Using RAC service is possible to implement load balance, connection failover, TAF, FCF, ONS, and other things to avoid that application get an error in case of some outage at the database side. You can read more here at Oracle RAC White Paper.
Besides failures, RAC allows the scalability of your environment. Is possible to extend the RAC nodes (online by the way) and add more power to your database cluster.
High Availability
High Availability is a union between Oracle RAC database and Oracle Clusterware but goes beyond that. Is a sum of a lot of features that guarantee application continuity. At least, the connection to your database continues to runs even in case of outage from one node and failover/switchover of the service between nodes.
Ludovico Caldara (http://www.ludovicocaldara.net/dba/) has an amazing session explaining HA and how to use correctly the server connection to reach the desired faulty tolerance.
Engineered System
If you think about, the best environment to runs a Clusterware for Oracle is Engineered System. There you will find tested interconnect network, redundant storage servers, redundant database nodes. And is not just Exadata, ODA is reliable for Silver Architecture too.
The Engineered system (besides the SW part) is made to have no single point of failure. If your network card stops, you have another one right there available to continue the wort at the same performance as the failed one. Even for catastrophic failures (full database node outage), you have others that are available. Again, reduced RTO in case of failure.
The Architecture
The Silver architecture references and uses all the HA features to have some level of application continuity, even if one HW outage affects the database. The basic design is something like this (took from the old version of MAA Reference Architecture doc):
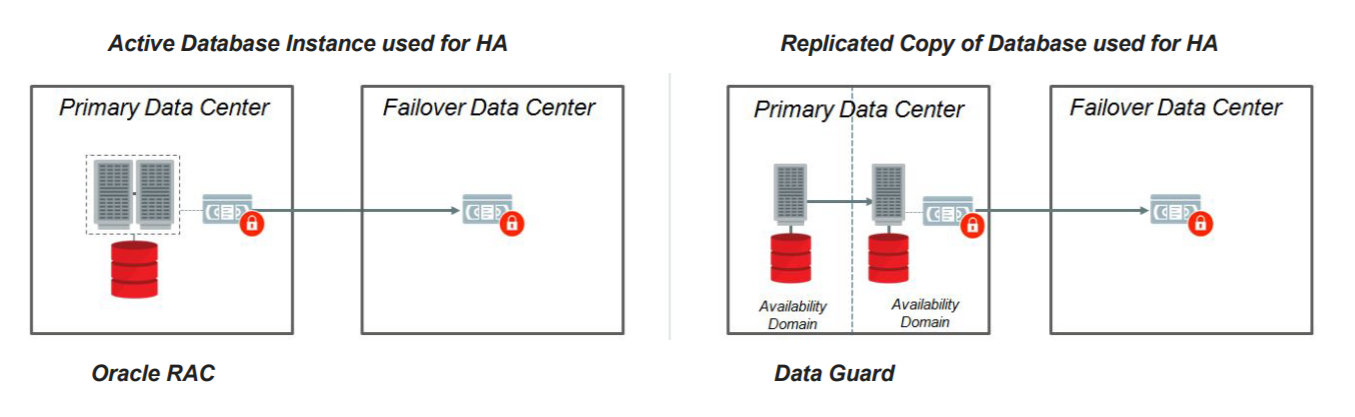 As you can see above, we have two options. Left uses RAC, and the right sides use DG. But both reside at the same DC. They are different for sure, some cons and pros. But at the and the outages, and how you deal with that, are similar.
As you can see above, we have two options. Left uses RAC, and the right sides use DG. But both reside at the same DC. They are different for sure, some cons and pros. But at the and the outages, and how you deal with that, are similar.
Check below the matrix of outages:
| Event | RPO | RTO |
| Hardware Error | Can be Zero | Zero |
| Database Error (SW) | Can be Zero | Can be Zero |
| Database Corruption | Can be Zero | Can be Zero |
| Site Outage | Can be bigger than zero | Bigger than Zero |
- Hardware Error: Since we are operating with HA, in case of HW error (CPU failure, until disk, or storage error) the RTO will be zero because of the design and the used features (ASM and RAC). Storage can be a single point of failure when you have one outage that affects the entire storage system. Maybe you can face data loss and the RTO will be bigger than zero since you don’t have another place to switchover/failover your database and you will need to restore the last backup.
- Database Error: This is related to SW error, like ORA-600 that creates an outage for your database. Different than Bronze Architecture, Silver doesn’t have a local single point of failure. If the failures affect just one node (or one side of the DG), the survive instance can deal and there is no outage and RTO and RPO will be zero. But, if you are afraid of one failure that affects the entire nodes of the RAC, the DG approach can be used for zero RTO. But for RPO, depends on the architecture. For RAC, if affect all nodes, can be bigger than zero (as Bronze), for DG, can be zero depending on the way that you configure it (or the versions evolved – think that the STB side can operate in a new release that bug not exists).
- Database Corruption: Can be logical or physical data block corruption. Same as Bronze. Depends where the corruption occurred (or how deeper it is), is possible that you need to restore from your last backup. For RAC, the remaining instance can correct the error caused by the failed instance and the RTO can be zero. For RPO, if the corruption occurred due to HW error (bad block), the DG can be used to restore it and it reduces to zero RPO. If no DG (RAC option) you need to restore from backup and can have RPO bigger than zero (think that bad block can corrupt the archivelog all well).
- Site Outage: This is the most complex because can involve unknown data loss and time to return the operations. Remember that you don’t have even the backup to restore the database. Compared with the Bronze, Silver Architecture suffers the same structural weekend, you have just one datacenter. So, there is no replication for backups (or the replicate backup copies are not up to date). And you first need to put the HW environment online to check until the point you potentially lost data.
As you can see, if compare with bronze architecture, the reduction is for RTO. “Can be” is not good enough since we still can suffer a data loss. The traditional Silver architecture still relies on the backup and replicated backups. So, in case of an outage that affects the Clusterware, like storage outage, you can have data loss. This is the reason that for Silver Architecture, even using Engineered Systems you can have data loss.
But is not just Exadata or expensive RAC node usages. You can use ODA and/with RAC One node to quick response in case of outage of one node. The idea is HA and Oracle Clusterware.
ZDLRA to protect Silver Architecture
If we check the new version of the MAA Architecture Reference the ZDLRA is there for Silver architecture to reduce the RPO to zero in almost every scenario. Even in a site outage, you can have your backup available to be used:
The Image is above taken from https://www.oracle.com/a/tech/docs/maa-overview-onpremise-2019.pdf
So, the outage matrix when using ZDLRA is:
| Event | RPO | RTO |
| Hardware Error | Zero* | Zero |
| Database Error (SW) | Zero | Can be Zero |
| Database Corruption | Zero* | Can be Zero |
| Site Outage | Zero* | Bigger than Zero |
All the outages can be protected and reach zero RPO. This is done using the real-time redo ZDLRA. Basically, as explained in my post about it, the ZDLRA became an archive_dest and the redo buffers/archivelogs are synced automatically at the ZDLRA side.
And again, in case of failure of the database the ZDLRA will generate a partial archivelog until the moment of failure. This means that for every failure HR/SW/Corruption ZDLRA will protect until the last SCN generated by the database. So, whatever the outage, you have one copy of all your transactions at an external place that is not linked (at any level like storage/HW) with your database.
One point of attention here, the replication between ZDLRA does not occur in real-time but tries to be done as soon as possible. So, in case of a complete site outage, if your database fails before the ZDLRA and the replication takes a place for the partial archivelog, you can have zero RPO with cross-site protection. If no, you can have on-site zero RPO.
How to use ZDLRA
I use my previous posts to show how to integrate ZDLRA and protect the architecture:
- Enroll database at ZDLRA
- Real-time Redo
- Real-Time Redo Sync mode
- ZDLRA Replication
- ZDLRA and clones to tape
Following the order above you cover everything: Starting with how to enroll the database, until configuring the real-time redo to reach zero RPO. And you will reach a configuration that will protect you from HW, SW, Database Corruption (and this includes multi-site protection and clone to tape offload).
In the same way as Bronze architecture, the basic Silver continues to rely upon the backup and replicated backup. This means that, in case you need to restore your database, you need to catalog and crosscheck all the backupsets. But with ZDLRA you have on rman catalog that is self-managed. So, even using the replicated ZDLRA you don’t need to catalog pieces or even crosscheck it. Everything that you see you can restore/recover and will be free of database block corruption too. This is a time saver during the outages crises.
If you need more information about ZDLRA itself you can read my blog series about ZDLRA. For ZDLRA and MAA integration, more details can be check at this doc about ZDLRA and MAA.
One last point that is important to add here. If you add ZDLRA at your environment, the same ZDLRA will protect your Bronze (Single Instances), Silver (RAC Databases), and even the Gold architecture (Multi-Site DG RAC+RAC).
Trying to protect without ZDLRA
In the same way that I made with the Bronze Architecture, let’s do one exercise: if we don’t have ZDLRA and want to increase the protection and reduce the RPO, what we can do? First, we can start decreasing the time when the backups of archivelogs are generated. As an example, instead of every 4 hours, every 15 minutes. Another option is reducing ARCHIVE_LAG_TARGET (this is good for ZDLRA too) and multiplex in different destination locations to have less loss of data in case of storage failures. But you still continue to have a gap between the place that runs your database and one external safe place.
And since that the storage still is the single point of failure, you need to survive this outage too. So, maybe you need to spread/mirror your diskgroups in different luns (that came from different controllers), even vertical configurations instead of horizontal disks aggregation. Or even using some kind of replication at the storage level.
As you can imagine, we are increasing the protection that is suitable for a few architectures. Some options (like storage replication) are not good for dataguard. Or even worst, can be more expensive than the ZDLRA approach (if you need to consider all the architectures that you have at your environment and needs to protect). Remember, ZDLRA is 100% integrated with MAA architecture.
Disclaimer: “The postings on this site are my own and don’t necessarily represent my actual employer positions, strategies or opinions. The information here was edited to be useful for general purpose, specific data and identifications were removed to allow reach the generic audience and to be useful for the community. Post protected by copyright.”
Pingback: MAA, Blueprints and On-Premise Architecture Reference | Fernando Simon