The Gold architecture for MAA is used to emphasis the application continuity. All the possible outages (planned or no) are protected by Oracle features. Here we are one step further and start to design using multi-site architecture. Data Guard, RAC, Oracle Clusterware, everything is there. But even with these, ZDLRA is still needed to allow complete protection.
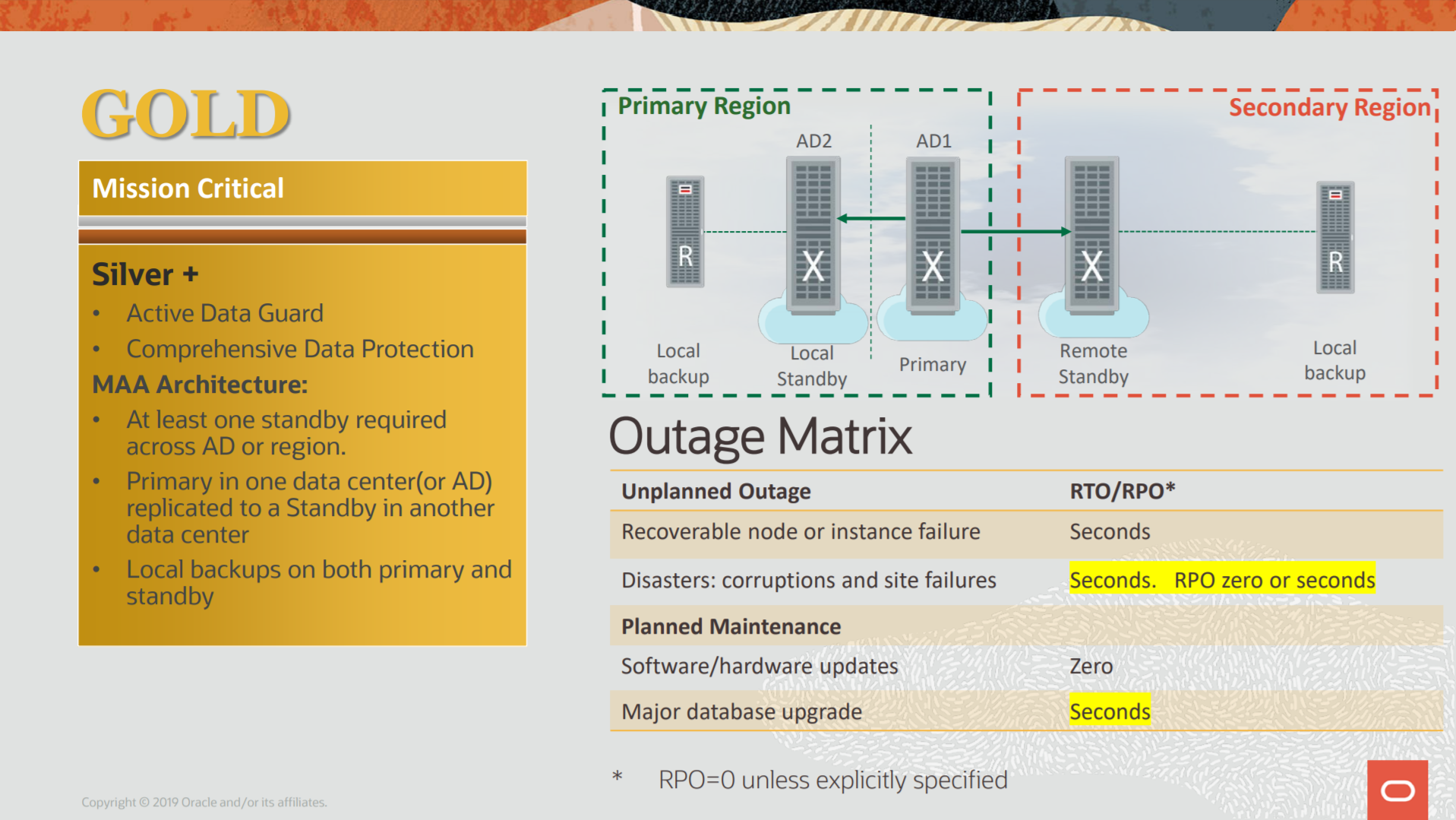
The image above taken from https://www.oracle.com/a/tech/docs/maa-overview-onpremise-2019.pdf.
With the MAA references, we have the blueprints and highlights how to protect them since the standalone/single instance until the multiple site database. But for Gold we are beyond RPO and RTO, they are important but application continuity and data continuity join to complete the whole picture.
Gold Architecture
If the Silver architecture focuses on High Availability (HA), the Gold focus in Disaster Recovery (DR). Even suffering a complete site outage is possible to survive with zero data loss, and beyond that, without loss of connection form the application side. Here the goal is critical databases and applications, those that can’t tolerate loss and need to have a quick response to outages.
If we check the base architecture, we can see the usage for Data Guard is fundamental/requirement. It can do intra-site protection (to provide a fast switchover/failover – or FarSync in case of long-distance for standby), and a multi-site synchronization.
Data Guard
The addition of Data Guard allow the environment to be HA (since is 100% compatible with RAC) but also includes data protection and disaster recovery. I will not cover all features of DG here, but will highlight some of them for Gold architecture (if you want to see all a comprehensive information, you can check this doc about HA):
- HA+DR: If you think about application continuity, the connection needs to continue even from a complete site outage. The RAC+DG is required for Gold architecture to have HA and DR. Services can be created to be automatically activated when the role change occurs.
- Active DG: Active DG is a superset of traditional DG, but it allows us to use some features and open (in read-only mode) the standby database. So, you can relocate some services to connect at standby and scalable more the architecture.
- Block Repair: When using Active DG is possible to recover one corrupted block (in primary as an example) reading it directly from the other side. Think that now, when you have on corruption, there is no impact on RPO and RTO.
- DML Standby: This is a new feature that was released for 19c (for 18c just with an underscore parameter) that allows you to send DML commands at standby and these will be applied at the primary database. This is important because if you need to connect at standby (to do a report from the application), and this application needs to record something (like an audit), now is possible. I made a post about this feature some time ago, you can read it here.
- Far-Sync: This feature allows what is called “zero data loss any distance” because to have zero RPO/RTO you need to operate DG at SYNC mode. But if your primary is in Tokyo and standby in London? The latency for every transaction will kill the performance. Using the Far-Sync you can have a local copy (with just part of your database) near your primary just to operate in SYNC the redo, and the Far-Sync will send in ASYNC mode to the standby. In the case of a primary site outage, the RPO/RTO can be zero due to SYNC mode, but the transaction will not be affected because the network trip between primary and far-sync are small.
- Standby-First Patch: This allows us to apply patches in standby first and continue the operation without interruption in the primary database. This is good because, in case of a software error, the fix can be applied at standby to bypass the bug. One example is the bug 29129534/25518372 that affects the backups/restores, this can be applied at standby, and standby backups can be used to restore/clone the database.
- Rolling Upgrades: with DG is possible to automatize part of the process for the upgrade of the database, this reduces a lot the RTO of your database in case of upgrades, or even the outage in case of planned maintenance. So, again, application continuity.
- Fast-Start Failover/Broker: The Broker allows you to use the fast-start failover and automatize the failure detection in case of an outage. The failover occurs automatically without intervention. So, the RTO can be reduced to zero even for complete site outage, data continues always available and the application continuity as well. I already wrote about it in the past and you can read the series here.
- Observer-Only/Health-Conditions: Sometimes we need to have better control of how the failover occurs, maybe we don’t want that it occurs (during network maintenance as on the example). So, is possible (at 19c version) put the FSFO in Observe-Only mode, and even change some checks that are valid or no to do the failover. I already wrote about this in a previous post, you can read it here.
All of these features help the Gold architecture to reduce the RPO and RTO to zero. If you check the most important is the Data Guard itself. You can run your database at a non-Engineered System machine and continue to have zero RPO. The Exadata usage is recommended, not required.
If you want to check more technical details please read this doc.
The Architecture
Look the traditional design from one old version of the MAA Reference Architecture doc:
And the outage matrix is:
| Event | RPO | RTO |
| Hardware Error | Zero | Zero |
| Database Error (SW) | Zero | Zero |
| Database Corruption | Zero | Zero |
| Site Outage | Zero* | Zero |
- Hardware Error: Even occurring HW error for the machines running the primary database, you can failover/switchover to the standby without losing data. And if your primary database runs over RAC, before switch/fails you need to have all nodes failings (what is not common).
- Database Error: For SW error, using DG, is not an outage that will cause data loss or even application continuity error. Remember that you can patch the standby. So, in case of some error, you can patch it and switchover and the application continues to runs without a gasp.
- Database Corruption: For logical and physical corruption both sides can be used to restore the exact block. So, there is no outage caused by this error (on both sides).
- Site Outage: The point for site outage is important because even with complete loss your data is in another site and read for usage. But you need to guarantee that both (PRY and STB) are synced
The architecture is pretty simple, you have your database replicated and synced in another datacenter. Is really recommended that you run in RAC (both sides) because in case of a simple HW error you don’t need to switchover/failover to standby.
A failover is usually a complex operation because involves a lot of things. You need that your application is able to connect on the other side. And is really important that both sides are synced. If you have one outage/maintenance at your standby and at the same time occurs one outage at primary, you don’t have where to switch/failover. So, DG environments are nice but require quite more care than a traditional instance (single or RAC). A lot of more external problems (like a network) can break a running DG. As an architect, we need to think in more details to reduce the simple point of failure. Like multiple network connections between DC’s.
One important detail in the design is that the synchronization between DC’s is done by DG. Solutions like replicated storage, extended environments can be not suitable (or even more complex and expensive) to sustain for Gold architecture. Keep it simple.
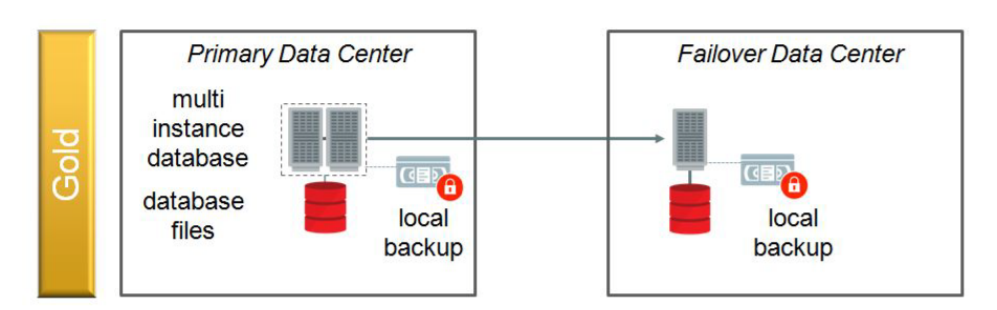
ZDLRA to protect Gold Architecture
If we check the new version of the MAA Architecture Reference the ZDLRA is there for Gold Architecture. But, why? Why we need ZDLRA if the RPO is Zero? I will explain:
The image above taken from https://www.oracle.com/a/tech/docs/maa-overview-onpremise-2019.pdf
The ZDLRA is there, mainly, to remove the Single Point of Failure. Look at the schematic above and imagine that you have a network outage between sites. What will be your RPO in case of failure? It will be huge, if you have an HW failure you will lose data (think in one environment that you are not running over Exadata). So, ZDLRA is your second line of defense. Is there to protects and guarantee the ZERO RPO even when the standby is offline.
Another point in the Gold architecture, the ZDLRA operates isolate (where each one protects the respective database), but ZDLRA from the primary site can be used by standby to read the backups (and vice-versa). And again, DG is the responsible database synced between DC’s.
The outage matrix when using ZDLRA is:
| Event | RPO | RTO |
| Hardware Error | Zero | Zero |
| Database Error (SW) | Zero | Zero |
| Database Corruption | Zero | Zero |
| Site Outage | Zero | Zero |
And again, in case of failure of the database the ZDLRA will generate a partial archivelog until the moment of failure. This means that for every failure HR/SW/Corruption ZDLRA will protect until the last SCN generated by the database. So, whatever the outage, you have one copy of all your transactions at an external place that is not linked (at any level like storage/HW) with your database.
How to use ZDLRA
The way to use ZDLRA is quite different for Gold. As explained before, the DG is responsible to sync the databases between sites, and even to provide the RPOT/RTO. At least the first line of protection. For the second line, we use ZDLRA.
So, more or less, the steps to have a Gold architecture are (I will use my previous posts as a guide):
- Create a DG environment (RAC + RAC synced with DG).
- Enrolling and protecting both sides with ZDLRA.
- ZDLRA and clones to tape
- ZDLRA, DG, and Rman configuration to avoid errors
Following these steps, you will have everything: Primary and Standby databases running with Oracle RAC and synced. Both will be protected by the correspondent ZDLRA, and the backups will be cloned to tapes as well. So, more than two lines/fronts of protection.
If you need more information about ZDLRA itself you can read my blog series about ZDLRA. For ZDLRA and MAA integration, more details can be check at this doc about ZDLRA and MAA.
Trying to protect without ZDLRA
So, if we don’t want to use ZDLRA for Gold architecture we can still have (more or less the same RPO/RTO), but we will have a single point of failure. As I already wrote above, if your standby is down (for any reason, planned or no), your primary is unprotected. Basically, you drop from Gold to Bronze, you will be unprotected and your RPO/RTO will be undefined. An this can be worst because maybe you need to follow some regulations that require you to have some kind of replication/protection for your primary database to avoid single point of failure.
It is really hard to design several levels of protection for outrages for Gold Architecture. We can replicate storages, but they need to be different here. Think that usually, the companies don’t have a lot of datacenters (they cost a lot do maintain). So, if your standby DC is down, we need to have the storage replicated to a third one, and this needs to be the same for Standby. In the end we are talking about four DC’s to have the same level of protection that ZDLRA can provide (and as you can imagine, they will be cheaper). And again, the same ZDLRA that protects Gold will protect Silver and Bronze architectures, and 100% integrated with MAA architecture.
References
I will list some references for Gold architecture that you can read from Oracle itself:
Oracle Maximum Availability Architecture (MAA)
Oracle MAA Reference Architectures (Old version)
Maximum Availability with Oracle Database 19c
Multitenant MAA Solutions (includes the “Aurous” Option)
Best Practices for Database Consolidation
Oracle® Database High Availability Overview
Oracle Active Data Guard Far Sync Zero Data Loss at Any Distance
Oracle Active Data Guard: Best Practices and New Features Deep Dive
Deploying the Zero Data Loss Recovery Appliance in a Data Guard Configuration
Disclaimer: “The postings on this site are my own and don’t necessarily represent my actual employer positions, strategies or opinions. The information here was edited to be useful for general purpose, specific data and identifications were removed to allow reach the generic audience and to be useful for the community. Post protected by copyright.”
Pingback: MAA, Blueprints and On-Premise Architecture Reference | Fernando Simon
Pingback: ZDLRA + MAA, Protection for Platinum Architecture | Fernando Simon