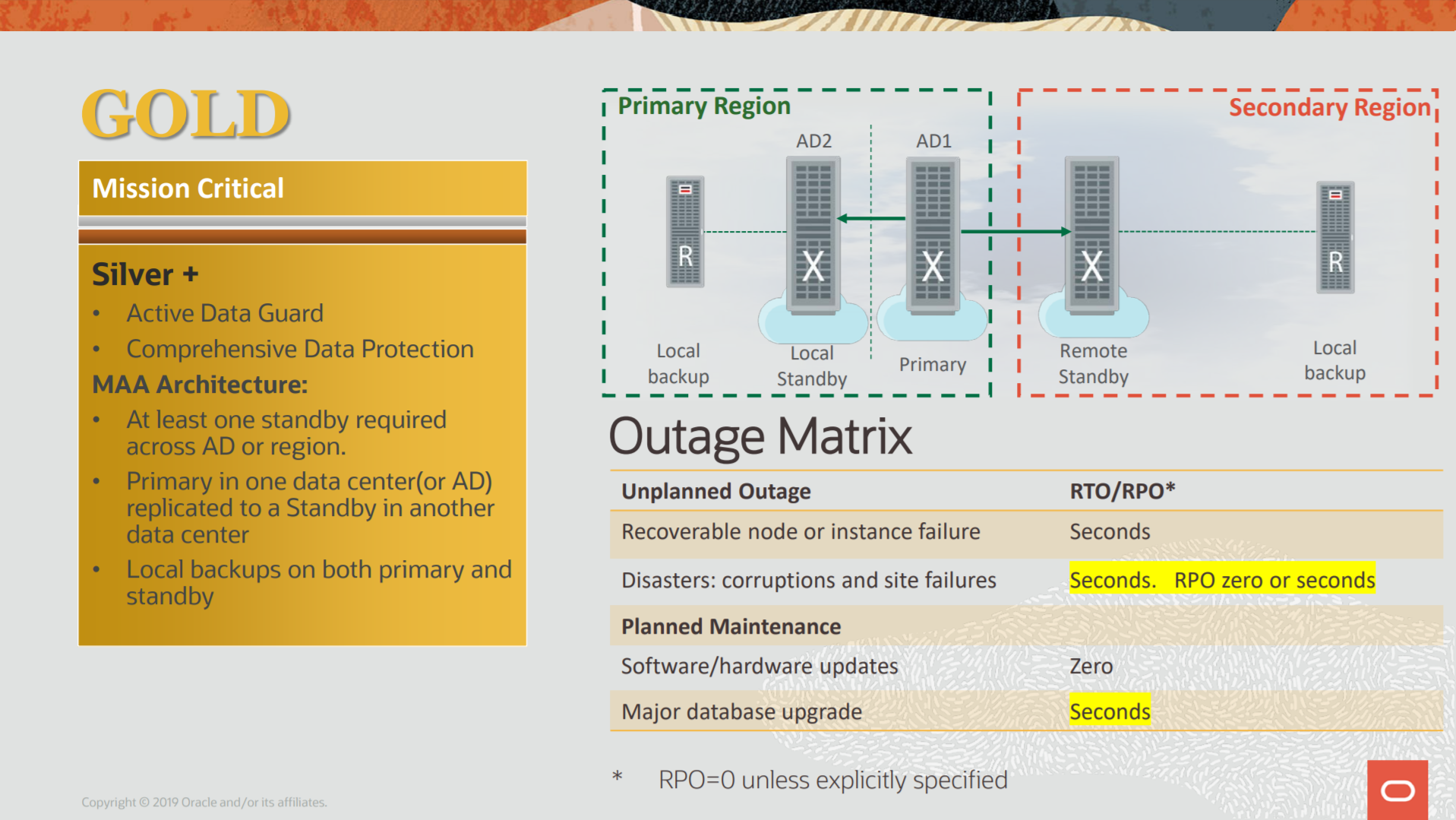
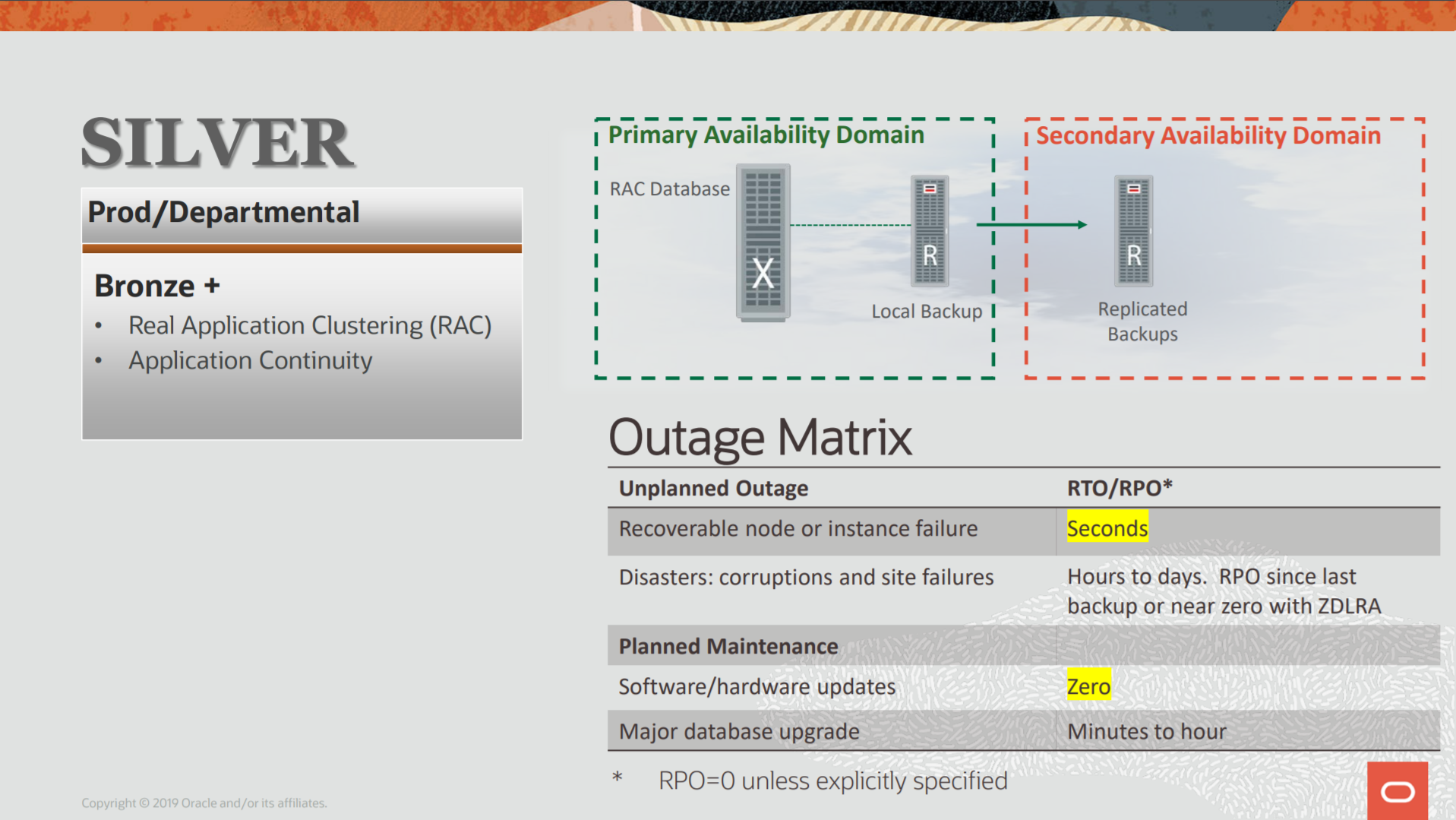
The replication for ZDLRA works differently than normal DataGuard, but you can reach almost the same level of multiple site protection with that. The replication for ZDLRA is not complicated but can be divided into several steps. Basically, to protect a database (since you have everything configure) is done linking the database with the protection policy that is replicated.
In my previous posts, I already wrote about all the steps to reach this configuration. Starting with an explanation about replication, how to configure the replication network between ZDLRA’s, how to configure the replication server, and how to create the replication config (that links everything is done before).
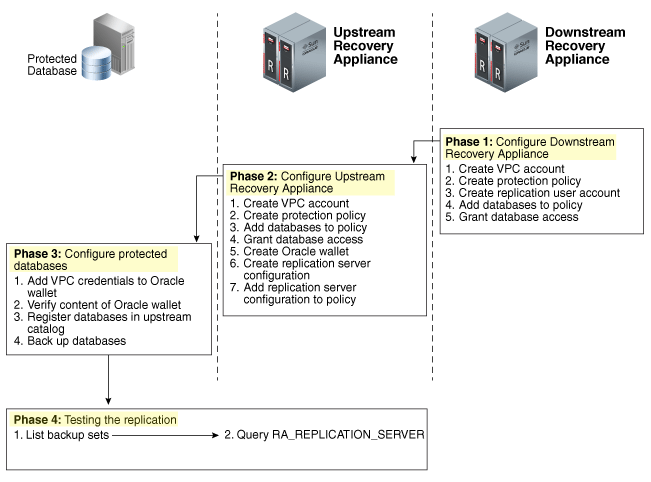
But most of the time we don’t need to pass through all of these steps. Usually, the ZDLRA is deployed with the replication network already configured, or you already deploy two ZDLRA’s that will operate replicated. This part I consider the “physical” part of the configuration because evolves network and details that we usually don’t touch after configured. The “logical” part comes after and evolves all the definitions about what policies will be replicated, which databases will be part of each policy, and so on. This “logical” configuration I explained in this previous post.
But it is important to know how it’s working to understand all the details. And if you need, you can check my posts about the replication for ZDLRA.
In this post, I will show more details on how the ZDLRA replication impact over the backup for your database, and show the protection occurs to reduce your RPO to a minimum.
Click here to read more…