The replication for ZDRLA works differently than a “normal” for Oracle Database that uses Data Guard (or even Golden Gate). The point is to replicate the ingested backup “as is” between ZDLRA’s and not datafile block replication. And, of course, it is completely different from tape clones.
ZDLRA replication is not just sent backup from one site to another, it is how to increase your protection and be part of the disaster recovery strategy. The replication does not occur just for “rman backups”, but also for archivelogs generated for Real-Time Redo. And adding, this is how you integrate ZDLRA at your MAA architecture that makes the difference and how you protect your environment and reach zero RPO. There are several points about replication, how it operates, modes, and integration for Oracle MAA universe. I will discuss some points here in this post.
The architecture
The architecture for ZDLRA replication it is simple. There are two important definitions:
- Upstream: It is the ZDLRA that receives the backup and forward it to another ZDLRA
- Downstream: Is the ZDLRA that receives the backup from another ZDLRA
Basically it is this:
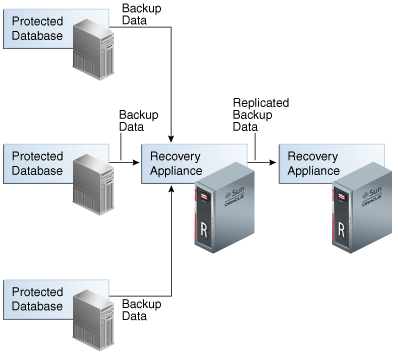
And the configuration can be:
- One-Way: The data flows in one way only, only one ZDLRA forwards the backups.
- Bi-Directional: Both ZDLRA’s send backups to each other. Is this case, the protected databases for each ZDLRA (usually one at the separated datacenter) are replicated between them since both operated as upstream/downstream.
- Hub-Spoke: One ZDLRA receives backups from several ZDLRA’s. And this “third” ZDLRA is responsible to archive to tape.
Is more or less like the picture below:
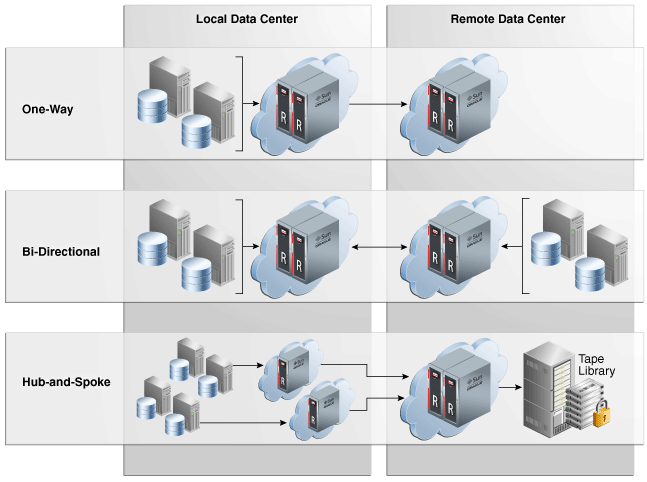
One important detail is that every ZDLRA can clone backups to tape. Is not just for Hub-Spoke design.
For network connections, it is possible to dedicate one network port just for replication to avoid concurrent usage. But is also possible to share the same physical interface to receive backup ingest too. Whatever the chosen mode, the network for replication is a different subnet.
Replication and Index
I already wrote about some details from the internals of ZDLRA, the Virtual Full Backup, what you need to understand it, and also about INDEX_BACKUP (here and here). And if you check the posts, you already understood that ZDLRA “sees” the rman backup in a different way.
But for replication, some details are important to hint here. The replication is done for (and just for) every backupset that is ingested, so, the virtual full backup is not replication. On the other hand, every downstream (ZDLRA that receives backup) constructs the virtual full backup.
This is important for several reasons, but doing in this way the replication occurs as soon as possible. To understand you need to join several features. One of common usage for ZDLRA is to reduce the backups loads doing just incremental (and usually at big environments with several TB’s), so, if ZDLRA waits to finish the virtual full backups generation to replicate this can take some time (depending the size of datafile – TB’s – can be hours). And if you wait for the generation of virtual full backup the data transfer/replicated can be huge, instead replicated the incremental (that can be just some GB’s), it will replicate TB’s of the full? And another point is the unprotect window that you can add over the environment, unprotect because you will have the backup in just on side for some time frame (and in case of a disaster your backups can be lost). And besides all of that, because of the replication, you will have both in both sides the incremental and the full validated against errors.
The usage
The replication for ZDLRA is more than just sending backups from one side to another. Again, ZDLRA is more than just reduce backup load, it is a pillar of your architecture. It is a key part of MAA architecture.
Who deploys ZDLRA usually have a big environment and need to protect several databases and several sites, and usually already follow MAA practices. But the point is that ZDLRA can be used to protected all databases, from the single database to the multi-site database. Wirth ZDLRA replication, the ZDLRA for each site can protect their site databases, but also replicate single databases to improve the disaster recovery strategy. And if you add the Tape Clones, the protection is complete.
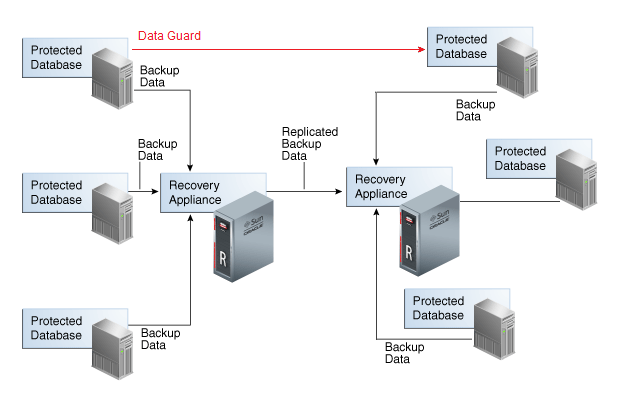
Think in the example above, we have two different sites. Some databases at the left side (Site A) are already protected by Oracle DG (but think that we can have the same from the right (Site B) replicating to the left too – Site A), and other databases without DG are protected by ZDLRA replication. What we have in this scenario:
- For DG protected databases: Backup is not replicated between ZDLRA’s because each side has its own backup. Replication is done by DG.
- Other databases: Backups replicated between ZDLRA’s (remember that can be multi-directional replication).
As you can see ZDLRA adds a new layer of protection/security for your environment and can be used to protect every kind of database. These kinds of architectures are shown in some details at Maximum Availability Architecture (MAA) – On-Premises HA Reference Architectures 2019, and here in this previous version of the same doc. I already made a Webinar discussing this too. And for Multi-site protection with ZDLRA, I already posted about it too, and you can read here. But whatever the mode of replication, you can reach ZERO RPO to all databases (even in case of site disaster) because you have the backups/archivelog needed to restore replication in other site (by DG or ZDLRA replication).
So, the usage of ZDLRA needs to be integrated into your architecture. From Bronze to Platinum databases it can be used.
Next Posts
There are several other details to cover about replication at ZDLRA. This post was just a little introduction about the ZDLRA native replication. The idea was pointing some points about how more complex than just sends backup from one site to another it is.
Adding more than one ZDLRA at your environment improve the strategy for MAA in several points. But the important is to think in the architecture of your environment, understand the features of ZDLRA, how you can use it to reduce the single point of failure and improve the disaster recovery strategy. And with replication for ZDLRA (and multiple ZDLRA’s) the zero RPO can be from the single database to the multi-site data guard database.
In the next posts, I will show how to configure replicated ZDLRA, how the replication, what changes for policies, and other details.
References:
- https://www.oracle.com/a/tech/docs/maa-overview-onpremise-2019.pdf
- https://docs.oracle.com/en/engineered-systems/zero-data-loss-recovery-appliance/19.2/ampdb/zero-data-loss-recovery-appliance-protected-database-configuration-guide.pdf
- https://docs.oracle.com/en/engineered-systems/zero-data-loss-recovery-appliance/19.2/amogd/zero-data-loss-recovery-appliance-owners-guide.pdf
- https://docs.oracle.com/en/engineered-systems/zero-data-loss-recovery-appliance/19.2/amagd/zero-data-loss-recovery-appliance-administrators-guide.pdf
Disclaimer: “The postings on this site are my own and don’t necessarily represent my actual employer positions, strategies or opinions. The information here was edited to be useful for general purpose, specific data and identifications were removed to allow reach the generic audience and to be useful for the community. Post protected by copyright.”
Very good article. Congrats!
Pingback: ZDLRA, Configuring Replication Network | Fernando Simon
Pingback: ZDLRA, Creating the Replication Server | Fernando Simon
Pingback: ZDLRA, Creating the Replication Config | Fernando Simon
Pingback: ZDLRA, Protecting Databases with Replication | Fernando Simon
Pingback: ZDLRA, How to Maintain the Native Replication | Fernando Simon
Pingback: Oracle’s Zero Data Loss Recovery Appliance – François Encrenaz