The replication for ZDLRA operates in several ways, from a single upstream/downstream config to a multiple replication config, but both are done using the same procedure. The process is not complicated but has some details that are needed to be aware to avoid reconstruct (or even loss) replicated data. In this post, I will show the details to create the replication config.
The base about how the replication works for ZDLRA I wrote in this post. And how to configure the replication network config in this other post. This network configuration needs to be done just when you are adding the replication after the ZDLRA has been deployed, if you already deployed with replication enabled it is not needed. The official documentation about replication can be found here.
Replication Topology
The topology for ZDLRA replication can vary, but basic is:
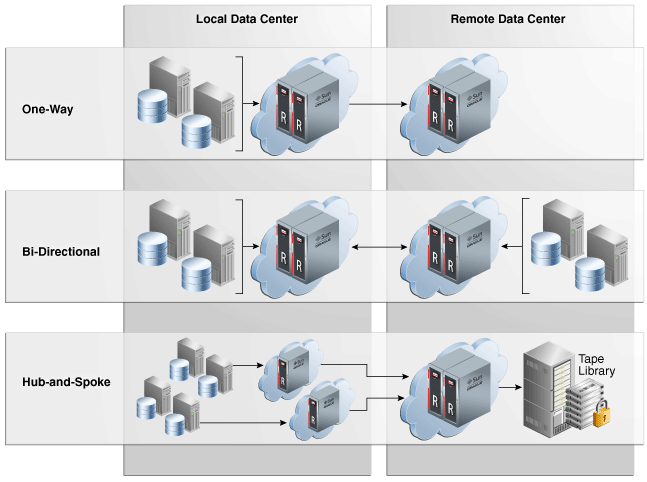
And the resume is:
- One-Way: The data flows in one way only, only one ZDLRA forwards the backups.
- Bi-Directional: Both ZDLRA’s send backups to each other. Is this case, the protected databases for each ZDLRA (usually one at the separated datacenter) are replicated between them since both operated as upstream/downstream.
- Hub-Spoke: One ZDLRA receives backups from several ZDLRA’s. And this “third” ZDLRA is responsible to archive to tape.
In any type of replication that you have exists:
- Upstream: It is the ZDLRA that receives the backup and forward it to another ZDLRA
- Downstream: Is the ZDLRA that receives the backup from another ZDLRA
Scenario
In this post (and others when I use the replication) I will use the “One-Way config” where I have one upstream and one downstream. But if you have other types, you just need to follow the same procedure and take care of details like user, wallets, and credentials.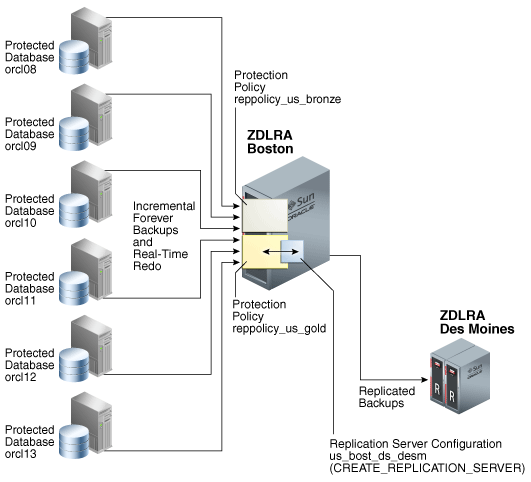
It will be:
- Upstream: ZDLRAS1.
- Downstream: ZDLRAS2.
Creating the Replication
The replication for ZDLRA operates differently than Oracle DG, it is native replication using a similar procedure than ingest backup at ZDLRA. I already wrote about this in my previous post (Replication and Index topic).
To configure the replication we use the procedure DBMS_RA.CREATE_REPLICATION_SERVER but before we need to check some details. The replication is done based on protection policy, so, all the databases linked with that will have the backups replicated. I will write about this in another post, in this post I will show how to create the replication config.
A user at downstream to receive replication
The ZDLRA replication requires that you use one specific user to send the backups from upstream to downstream. This user is created just in the downstream ZDLRA and never needs to be used to connect using rman.
The form/best practices to create user is REPUSER_FROM_[ZDLRA_UPSTREAM_DB_NAME]. Doing this you know the source of connection (when your downstream receives backup from more than one upstream).
So, the first step is to create the user at downstream:
[root@zdlras2n1 ~]# /opt/oracle.RecoveryAppliance/bin/racli add vpc_user --user_name=repusr_from_zdlras1 [repusr_from_zdlras1] New Password: Mon Nov 25 23:34:50 2019: Start: Add vpc user repusr_from_zdlras1. Mon Nov 25 23:34:51 2019: Add vpc user repusr_from_zdlras1 successfully. Mon Nov 25 23:34:51 2019: End: Add vpc user repusr_from_zdlras1. [root@zdlras2n1 ~]#
To allow the upstream connect at downstream to send the backup is needed to create one wallet at upstream ZDLRA with credentials from the repuser create in the first step. The wallet can be stored in one shared filesystem to allow both nodes of the cluster to access is, or each node can store at one folder (but path needs to be the same in both).
The wallet needs to be ALO (auto-login) and can be shared (if you have one). To create the wallet at upstream we need to do:
[root@zdlras1n1 ~]# su - oracle Last login: Mon Nov 25 23:43:26 CET 2019 on pts/3 [oracle@zdlras1n1 ~]$ mkdir /radump/wallrep [oracle@zdlras1n1 ~]$ [oracle@zdlras1n1 ~]$ mkstore -wrl /radump/wallrep -createALO Oracle Secret Store Tool Release 19.0.0.0.0 - Production Version 19.3.0.0.0 Copyright (c) 2004, 2019, Oracle and/or its affiliates. All rights reserved. [oracle@zdlras1n1 ~]$
And after that, we create the credential with username and password that was created at downstream:
[oracle@zdlras1n1 ~]$ mkstore -wrl /radump/wallrep -createCredential zdlras2-rep.oralocal:1522/zdlras2 repusr_from_zdlras1 repuser Oracle Secret Store Tool Release 19.0.0.0.0 - Production Version 19.3.0.0.0 Copyright (c) 2004, 2019, Oracle and/or its affiliates. All rights reserved. [oracle@zdlras1n1 ~]$ [oracle@zdlras1n1 ~]$ mkstore -wrl /radump/wallrep -listCredential Oracle Secret Store Tool Release 19.0.0.0.0 - Production Version 19.3.0.0.0 Copyright (c) 2004, 2019, Oracle and/or its affiliates. All rights reserved. List credential (index: connect_string username) 1: zdlras2-rep.oralocal:1522/zdlras2 repusr_from_zdlras1 [oracle@zdlras1n1 ~]$
The credential name you can define, but I usually specify it with the same pattern as EZCONNECT. Doing this, I directly know where this credential is.
DBMS_RA.CREATE_REPLICATION_SERVER
The third and last step to create the replication is to call the procedure to create the configuration at upstream. This is done just at upstream and it uses the wallet create at step two.
So, we use DBMS_RA.CREATE_REPLICATION_SERVER with parameters:
- replication_server_name: Name for the downstream server. You can define the name that you want.
- sbt_so_name: It will be always “libra.so”.
- catalog_user_name: Is the user that will connect using the wallet. Always RASYS.
- wallet_alias: The credential name that you defined what wallet.
- wallet_path: Where the wallet is located.
- max_streams: Max number of concurrent replication streams. The default value is 4.
The replication information can be checked at RASYS.RA_REPLICATION_SERVER tables that store all the information for replicated servers at your upstream.
So, to create the replication configuration:
[oracle@zdlras1n1 ~]$ sqlplus rasys/change^Me2
SQL*Plus: Release 19.0.0.0.0 - Production on Sun Dec 22 20:46:51 2019
Version 19.3.0.0.0
Copyright (c) 1982, 2019, Oracle. All rights reserved.
Last Successful login time: Sun Dec 22 2019 20:33:15 +01:00
Connected to:
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production
Version 19.3.0.0.0
SQL> SELECT COUNT(*) FROM RA_REPLICATION_SERVER;
COUNT(*)
----------
0
SQL>
SQL> BEGIN
2 DBMS_RA.CREATE_REPLICATION_SERVER (
3 replication_server_name => 'zdlras2_rep',
4 sbt_so_name => 'libra.so',
5 catalog_user_name => 'RASYS',
6 wallet_alias => 'zdlras2-rep.oralocal:1522/zdlras2',
7 wallet_path => 'file:/radump/wallrep');
8 END;
9 /
PL/SQL procedure successfully completed.
SQL> SELECT COUNT(*) FROM RA_REPLICATION_SERVER;
COUNT(*)
----------
1
SQL>
One important point here is the “max_streams” parameter. It needs to be tuned, if you are replicating more databases, maybe is good to increase this value. You can check the queue just select the “rasys.ra_task” table and verify if there are waiting for tasks for replication. Of course, this depends on the size of your files too.
Replication
The steps described here are just the small part for replication. We just created the replication server config at upstream (wallets and information) and downstream (username). But we still not finish the configuration for replication workflow:
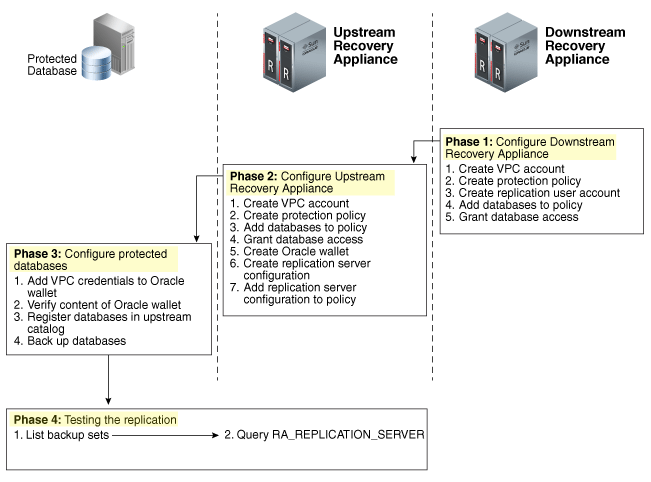
But the missing past is related to “logical” definition, like policies that will be replicated and databases that are linked with these policies. The basic configuration (replication server config) was done in this post, and at previous posts.
At next post will show how to configure the backup policies and the details that you need to take care to correctly define it. If you want to understand more about protection policies you can check the post that I made about it.
Disclaimer: “The postings on this site are my own and don’t necessarily represent my actual employer positions, strategies or opinions. The information here was edited to be useful for general purpose, specific data and identifications were removed to allow reach the generic audience and to be useful for the community. Post protected by copyright.”