Oracle Maximum Availability Architecture (MAA) means more than just Data Guard or Golden Gate to survive outages, is related to data protection, data availability, and application continuity. MAA defines four reference architectures that can be used to guide during the deploy/design of your environment, and ZDLRA is there for all architectures.
 Image above taken from https://www.oracle.com/a/tech/docs/maa-overview-onpremise-2019.pdf.
Image above taken from https://www.oracle.com/a/tech/docs/maa-overview-onpremise-2019.pdf.
With the MAA references, we have the blueprints and highlights how to protect them since the standalone/single instance until the multiple site database. The MAA goal is to survive an outage but also sustain: Data Availability, Data Protection, Performance (no impact), Cost (lower cost), and Risk (reduce).
But we can resume to two points:
- Recovery Point Objective (RPO): Means the point of time until you can restore/recover your database in case of an outage. Basically, how much data you can lose.
- Recovery Time Objective (RTO): In case of an outage, how much time you need to put everything runs operationally. In resume, time that your database will be offline.
The ideal is having zero for these, zero RPO and RTO. And if you follow the guidelines form MAA reference, you can reduce both to zero. But of course, that this depends on the requirements that you have, and the architecture that you are following. But for sure that the databases (and data) need to survive for planned and unplanned outages, both need to be addressed at the plan and architecture design.
As wrote in my previous post, I will cover all the architectures for On-Premise and discuss why ZDLRA is the pillar for every MAA architecture design.
Bronze Architecture
Bronze architecture is linked to environments that the database is running in a single instance. There is no RAC, no Engineered Systems, no redundancy. Is the traditional environment: Database Server + Storage + Backup. But the point here is in case of failure that needs to restore data the point from the last backup is enough.
The basic design is something like this (took from the old version of MAA Reference Architecture doc):
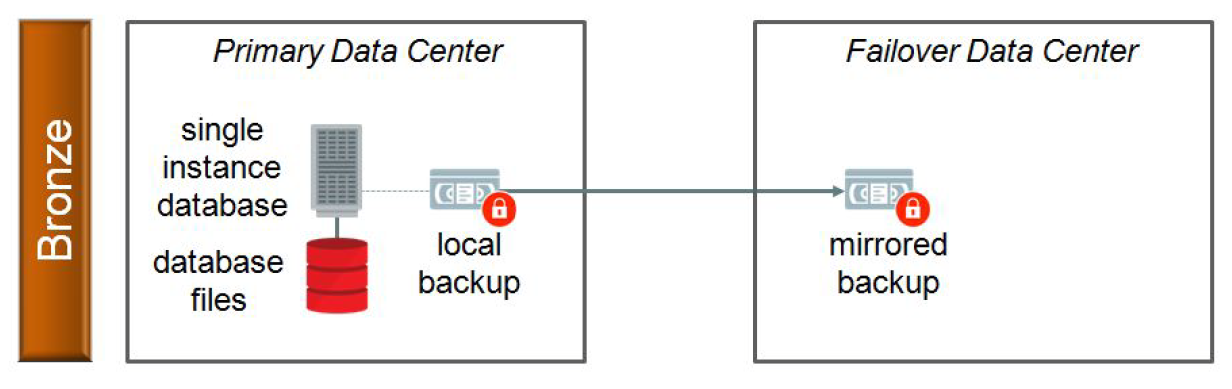 Usually, these databases are from DEV/TST environments. But can be related to PROD databases as well, like some HR databases, control databases (printer copies, or other resources), or other satellite databases. The point is that you (and your enterprise) defines what is important, the service levels for your databases. Basically, in case of an outage, your enterprise does not stop working.
Usually, these databases are from DEV/TST environments. But can be related to PROD databases as well, like some HR databases, control databases (printer copies, or other resources), or other satellite databases. The point is that you (and your enterprise) defines what is important, the service levels for your databases. Basically, in case of an outage, your enterprise does not stop working.
The matrix for outages is:
| Event | RPO | RTO |
| Hardware Error | Bigger than Zero | Bigger than Zero |
| Database Error (SW) | Zero | Bigger than Zero |
| Database Corruption | Since the last backup | Bigger than Zero |
| Site Outage | Can be bigger than zero | Bigger than Zero |
- Hardware Error: Think about HW error, can be from CPU failure, until disk, or storage error. But remember that you are running in a non-redundancy or HA environment. So, in case of failure (like disk/storage) maybe you need to return from data from the last backup (RPO > than zero). And the RTO will be more than zero since you don’t have another place to switchover/failover your database and needs to restore the backup.
- Database Error: This is related to SW error, like ORA-600 that creates an outage for your database. Usually, this kind of error not lead to data loss. So RPO will be zero, you can recover your database until the moment of failure. But until you solve the issue, the database will be offline and the RTO will be bigger than zero.
- Database Corruption: Can be logical or physical data block corruption. Depends where the corruption occurred (or how deeper it is), is possible that you need to restore from your last backup. And the RTO will be bigger than zero due shutdown to restore/recover the database.
- Site Outage: This is the most complex because can involve unknown data loss and time to return the operations. Remember that you don’t have even the backup to restore the database. We are at bronze architecture, so, there is no replication for backups (or the replicate backup copies are not up to date). And you first need to put the HW environment online to check until the point you potentially lost data.
The point from Bronze architecture is that you don’t have any guarantee that you can survive to a minimal outage, and you don’t have application continuity. Is not just survive, but your data can be lost (two failures at RAID 5 as an example). HW error (like PSU) will leave your database (an application down), so, no application continuity as well.
And this is the point for Bronze architecture that needs to be clear, there is no HA or another place to switchover/failover. Most of the time the only way to survive is to restore/recover databases from backups. Even using options like flashback database, PDB’s, backup at Cloud, and Oracle Restart, the last made backup will be the point for RPO.
But sometimes occurs that we need to sustain some databases that are more important that appear to be. If some HR database (from small that it is) became out, can be critical. Sometimes occurs that we neither know about that. Understand correctly the service level agreements (SLA) is critical.
ZDLRA to protect Bronze Architecture
The usage of ZDLRA at your architecture improves the reliability and recoverability of your environment. The ZDLRA features will allow you to reach zero RPO and will guarantee that your backup will be always available to be used. And I already wrote in my first post of this series, today, there is no MAA design without ZDLRA included. And this is defined by MAA Architecture Reference, not by me.
The common design reference to Bronze is:
 But even a simple design without the replicated ZDLRA can guarantee zero RPO. The outage matrix in this scenario is:
But even a simple design without the replicated ZDLRA can guarantee zero RPO. The outage matrix in this scenario is:
| Event | RPO | RTO |
| Hardware Error | Zero* | Bigger than Zero |
| Database Error (SW) | Zero | Bigger than Zero |
| Database Corruption | Zero* | Bigger than Zero |
| Site Outage | Zero* | Bigger than Zero |
If you compare, for all outages we can reach zero RPO. This occurs because of the real-time redo usage from ZDLRA. With that, as explained in my post about it, the ZDLRA became an archive_dest for your database. In the same way that DG does, the redo buffers are synced automatically at the ZDLRA side.
And even more important, in case of failure of the database, the ZDLRA will generate a partial archivelog until the moment of failure. This means that for every failure HR/SW/Corruption ZDLRA will protect until the last SCN generated by the database. So, whatever the outage, you have one copy of all your transactions at an external place that is not linked (at any level like storage/HW) with your database.
For site outage is needed a little more attention. The replication between ZDLRA does not occur in real-time but tries to be done as soon as possible. This means that in case of a site outage, it will depend on the way that occurred (who failed first) and if the replication takes a place for the partial archivelog. If yes, you can have zero RPO with cross-site protection. If no, you can have on-site zero RPO.
ZDLRA does not touch at RTO. If you want to improve the RTO, you need to upgrade to other architectures like Solver, Golden, and so on.
How to use ZDLRA and protect architecture
I will use my previous posts to show how to integrate ZDLRA for Bronze architecture:
- Enroll database at ZDLRA
- Real-time Redo
- Real-Time Redo Sync mode
- ZDLRA Replication
- ZDLRA and clones to tape
Following the order above you cover everything that is needed to protect the Bronze architecture. Starting how to enroll the database, until configuring the real-time redo to reach zero RPO. And you will reach a configuration that will protect you from HW, SW, Database Corruption. And even have the multi-site protection and clone to tape offload.
But is not just real-time redo protection that will help. Remember that for Bronze architecture it relies upon the backup, and also remember that for ZDLRA the rman catalog is self-managed. This means that you don’t need to catalog pieces or even crosscheck it when need to recover. Everything that you see inside the catalog you can restore/recover and will be free of database block corruption too. This is a time saver during the outages crises.
And I will add that for real-time redo you can protect even the standard edition, you don’t need to pay a Data Guard license to use it. So, zero RPO too.
If you need more information about ZDLRA itself you can read my blog series about ZDLRA.
Without ZDLRA
Doing and exercise: if we don’t have ZDLRA and want to increase the protection and reduce the RPO for Bronze architecture, what we can do? As you can imagine, we can start decreasing the time when the backups of archivelogs are generated. As an example, instead of every 4 hours, every 15 minutes. Another option is reducing ARCHIVE_LAG_TARGET (this is good for ZDLRA too) and multiplex in different destination locations to have less loss of data in case of storage failures. But you still continue to have a gap between the place that runs your database, and one external safe place.
And going deeper, you need to survive to do storage outage too, so, maybe you spread/mirror your diskgroups in different luns (that came from different controllers), or even vertical configurations instead horizontal disks aggregation. Or even using some kind of replication at the storage level.
But the point is that you are increasing the protection that hit just some database architectures. Some options (like storage replication) are not suitable for data guard. Or even worst, can be more expensive than the ZDLRA approach if you need to consider all the architectures that you are using. Remember, ZDLRA is 100% integrated with MAA architecture.
And for sure that in your environment you have more than just single instance databases. You have RAC, Exadata, or even DG multi-site databases to protect. So, your design needs to cover all of these, and ZDLRA is the perfect fit to protect all of them.
Disclaimer: “The postings on this site are my own and don’t necessarily represent my actual employer positions, strategies or opinions. The information here was edited to be useful for general purpose, specific data and identifications were removed to allow reach the generic audience and to be useful for the community. Post protected by copyright.”
Pingback: MAA, Blueprints and On-Premise Architecture Reference | Fernando Simon
Pingback: ZDLRA + MAA, Protection for Silver Architecture | Fernando Simon