Some months ago I got one error with Oracle Data Guard and now I had time to review it again and write this article. Just to be clear since the beginning, the discussion here is not about the error itself, but about the circumstances that generated it.
The environment described here follows, at least, the most common best practices for DG by Oracle. Have 1 dedicated server for each one: Primary Database, Physical Standby Database, and Observer. The primary and standby reside in different data centers in different cities, dedicated network for interconnecting between sites, protection mode was Maximum Availability, and runs with Fast-Start Failover enabled (with 30 seconds for threshold). The version here is 12.2 but will be the same for 19c. So, nothing so bad in the environment, basic DG configuration trying to follow the best practices.
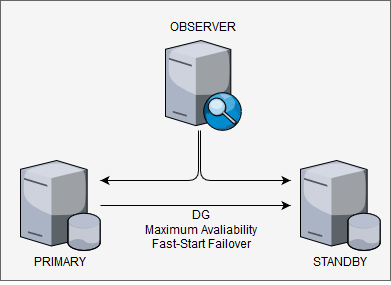 But, one day, application servers running, primary Linux DB server running, but the database itself down. Looking for the cause, found in the broker log (simulated in my test environment):
But, one day, application servers running, primary Linux DB server running, but the database itself down. Looking for the cause, found in the broker log (simulated in my test environment):
03/10/2019 12:48:05
LGWR: FSFO SetState(st=2 "UNSYNC", fl=0x2 "WAIT", ob=0x0, tgt=0, v=0)
LGWR: FSFO SetState("UNSYNC", 0x2) operation requires an ack
Primary database will shutdown within 30 seconds if permission
is not granted from Observer or FSFO target standby to proceed
LGWR: current in-memory FSFO state flags=0x40001, version=46
03/10/2019 12:48:19
A Fast-Start Failover target switch is necessary because the primary cannot reach the Fast-Start Failover target standby database
A target switch was not attempted because the observer has not pinging primary recently.
FSFP network call timeout. Killing process FSFP.
03/10/2019 12:48:36
Notifying Oracle Clusterware to disable services and monitoring because primary will be shutdown
Primary has heard from neither observer nor target standby
within FastStartFailoverThreshold seconds. It is
likely an automatic failover has already occurred.
The primary is shutting down.
LGWR: FSFO SetState(st=8 "FO PENDING", fl=0x0 "", ob=0x0, tgt=0, v=0)
LGWR: Shutdown primary instance 1 now because the primary has been isolated
And in the alertlog:
2019-03-10T12:48:35.860142+01:00 Starting background process FSFP 2019-03-10T12:48:35.870802+01:00 FSFP started with pid=30, OS id=6055 2019-03-10T12:48:36.875828+01:00 Primary has heard from neither observer nor target standby within FastStartFailoverThreshold seconds. It is likely an automatic failover has already occurred. Primary is shutting down. 2019-03-10T12:48:36.876434+01:00 Errors in file /u01/app/oracle/diag/rdbms/orcl/orcl/trace/orcl_lgwr_2472.trc: ORA-16830: primary isolated from fast-start failover partners longer than FastStartFailoverThreshold seconds: shutting down LGWR (ospid: 2472): terminating the instance due to error 16830
But this is (and was) not a DG problem, the DG made what was design to do. Primary lost the communication with the Standby and Observer and after the Fast-Start Failover threshold, FSFP killed the primary because it doesn’t know if it was evicted and want to avoid split-brain (or something similar). Worked as designed!
As I wrote before the main question here is not the ORA-XXXX error, but the circumstances. In this case, by design definition (and probably based in the docs), chosen to put the observer in the same site than standby. But, because one failure in the standby datacenter (just in the enclosure that runs blades for Oracle stuffs, the application continued to runs), the entire database was unavailable. One outage in standby datacenter, shut down the primary database even DG running in Maximum Availability mode.
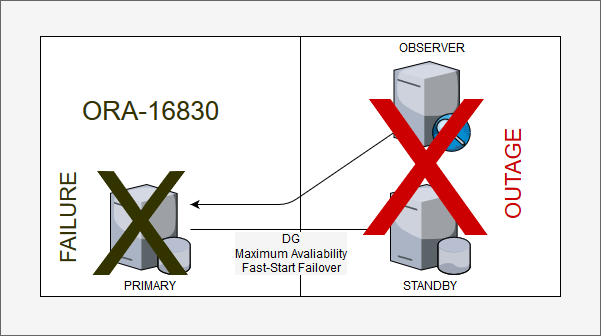
As you can imagine, because of the design decision “where to put the observer”, everything was down. If the observer was running in the primary datacenter, nothing supposed to occurs. But here it is the point for this post: “Where you put the Observer?”, “Primary site? Standby site?”, and “Why?”, “How you based this decision?”. It appears to be a simple question to answer, but there are a lot of pros and cons, and there is not much information about that.
If you search in the Oracle docs they recommend to put the observer in a third datacenter, isolated from the others, or in the same network than application, or in the standby datacenter. Here: https://www.oracle.com/technetwork/database/availability/maa-roletransitionbp-2621582.pdf (page 9). But, where are the pros and cons of the decision? And how many clients have a third datacenter? And if you search about were put the observer over the google, the 99% spread the same information (that go in the opposite of docs) “primary site”. But again, “Why?”.
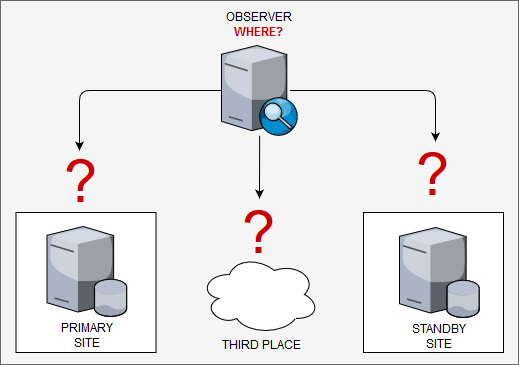 The observer in primary site:
The observer in primary site:
- Pros: Protect for most failures (primary DB crash failure, DB logical crash as an example), low impact network issues for the observer (usually same LAN than primary).
- Cons: Not protect (not switch) in case of a whole primary datacenter failure.
- When to use: When you want to avoid “false positive” switches in case of network problems against standby datacenter or you “not trust” in standby datacenter. Or because all transactions are important (will explain later).
The observer in standby site:
- Pros: Protect against whole primary datacenter failure.
- Cons: Heavy dependency from the network between sites (need even multiple paths), can suffer “false positives” switches since standby site decides even if primary is running correctly (similar than related here) or maybe disable auto reinstate of primary at the broker. When the database is more important than transactions, maybe Maximum Availability is not suitable (explain later).
- When to use: When you want to protect the database and when your system and network infrastructure between datacenter are reliable.
Observer Third datacenter:
- Pro: Cover all scenarios of failures.
- Cons: Heavily dependent on the good network to avoid “false positives” or will suffer from fast-start failover disabled. It will be more expensive.
- When to use: When you want to protect for most of the possible scenarios.
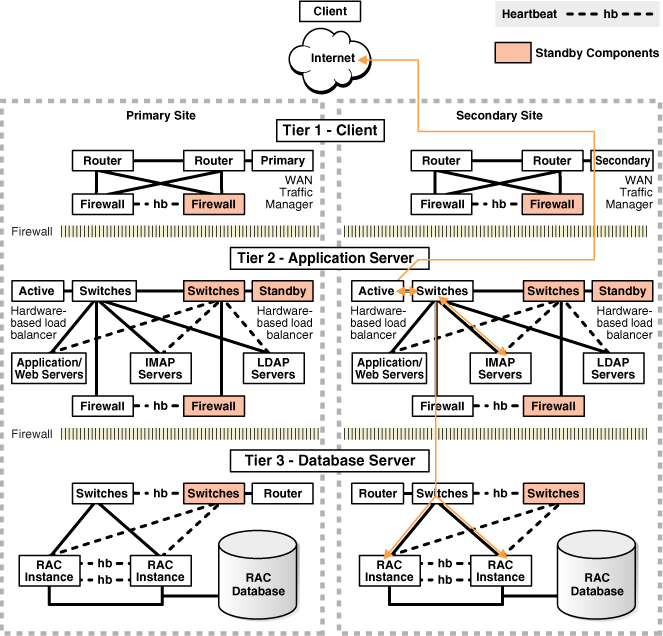
Bellow just one idea about a good design for high availability for database and applications. This came directly from the Oracle docs about “Recovering from Unscheduled Outages – https://docs.oracle.com/database/121/HABPT/E40019-02.pdf”
Above I talked about transactions and Maximum Availability that it is deeply related here. Remember that the primary database shut down only after the fast start failover threshold? This means that the primary database received transactions for 30 seconds before shutting down. If you put the observer in standby site you can suffer from data loss (of course that failover, by design, means that) because standby side decides everything.
If you do that, maybe you need to operate in Maximum Protection to have zero data loss. This is more clear, or critical if your database receives connections from applications that are not in the same datacenter and can connect in both at the same time. In Maximum Protection, you avoid that primary commit data in moments of possible failures, but you will put some overhead in every transaction operating in sync mode (https://www.oracle.com/technetwork/database/availability/sync-2437177.pdf). So, you need to decide if have database running is more important than transactions.
Of course that every strategy has pros and cons. The observer in the primary is easier, maybe it can allow you to use less strict protection and continue to have high transaction protection, but not handle full datacenter failure. The observer in standby can protect from datacenter failure but it is possible that you need to handle more “false positive” switches of primary DB or even complete primary shutdown (as related here) in the case of a standby datacenter failure. Adding the fact that maybe your application needs to allow some data loss, or if not, you may need to operate in maximum protection. Observer in the third site can be the best option for data protection, but will be more expensive and heavily network and operational dependent.
As you can see, there is not an easy design. Even a simple choice, like the observer location, will leave plenty of decisions to be made. With Oracle 12.2 and beyond (including 19c) you have better options to handle it, I will pass over this in the next post about multiple observers, but there is no (yet) 100% solution to cover all possible scenarios.
Martin Bracher, Dr. Martin Wunderli, and Torsten Rosenwald made a good cover of this in the past. You can check the presentations here:
- https://www.doag.org/formes/pubfiles/303232/2008-K-IT-Bracher-Dataguard_Observer_ohne_Rechenzentrum.pdf
- https://www.trivadis.com/sites/default/files/downloads/fsfo_understood_decus07.pdf
- https://www.doag.org/formes/pubfiles/218046/FSFO.pdf
I recommend read the docs too:
- https://docs.oracle.com/en/database/oracle/oracle-database/12.2/dgbkr/data-guard-broker.pdf
- https://www.oracle.com/technetwork/database/availability/maa-roletransitionbp-2621582.pdf
- https://docs.oracle.com/en/database/oracle/oracle-database/12.2/sbydb/data-guard-concepts-and-administration.pdf
- https://docs.oracle.com/database/121/HABPT/E40019-02.pdf
If you have comments, please do it.
Nice explanation! Thanks for sharing !
Pingback: Observer, More Than One | Blog Fernando Simon
Pingback: Observer, Quorum | Blog Fernando Simon
Awesome explanation. In my test, i did put the observer in the primary. And true enough, when my primary die, its not able to come back. 😉
Pingback: ZDLRA + MAA, Protection for Gold Architecture | Fernando Simon
Complexity simplified, thank you for sharing your experience in such details.