This article closes the series for DG and Fast-Start Failover that I covered with more details the case of isolation can leverage the shutdown of your healthy/running primary database. The “ORA-16830: primary isolated from fast-start failover partners”.
In the first article, I wrote about how one simple detail that impacts dramatically the reliability of your MAA environment. Where you put your Observer in DG environment (when Fast-Start Failover is in use) have a core figure in case of outages, and you can face Primary isolation and shutdown. Besides that, there is no clear documentation to base yourself on “pros and cons” to define the correct place for Observer. You read more in my article here.
In the second article, I wrote about one new feature that can help to have more protected and cover more scenarios for Fast-Start Failover/DG. Using Multiple Observers you can remove the single point of failure and allow you to put one Observer in each side of your environment (primary, standby, and a third one). You can read more in my article here.
In this last article, I discuss how, even using all the features, there is no perfect solution. Another point is discussing here is how (maybe) Oracle can improve that. Below I will show more details that even multiple observers continue to shutdown a healthy primary database. Unfortunately, it is a lot of tech info and is a log thread output. But you can jump directly to the end to see the discussion about how this can be improved.
Fast-Start Failover and Multiple Observers
Because of the design of Fast-Start Failover, Broker, and DG even using multiple observers, we continue to have the decision (to failover or no the database) based on just one observer report. The others are just backup from the master, but what they saw not count when the failover scenario hit the environment. Even if the Primary Database can receive connections from the other two observers, but not receive the connection master (and standby), it decides to shutdown because it is “isolated”.
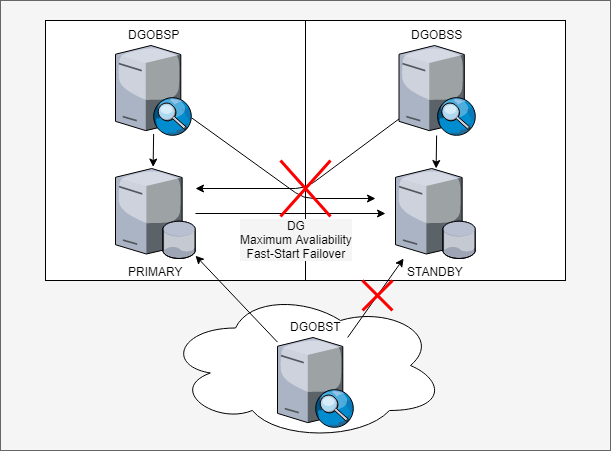
Look the example below where I have three observers (one in each site and a third one in the “cloud”):

The image above can be translated in this config for Broker where the Master Observer it is “dbobss” (that resides in standby datacenter):
DGMGRL> show fast_start failover;
Fast-Start Failover: ENABLED
Threshold: 240 seconds
Target: orcls
Observers: (*) dbobss
dbobsp
dbobst
Lag Limit: 30 seconds (not in use)
Shutdown Primary: TRUE
Auto-reinstate: TRUE
Observer Reconnect: 10 seconds
Observer Override: FALSE
Configurable Failover Conditions
Health Conditions:
Corrupted Controlfile YES
Corrupted Dictionary YES
Inaccessible Logfile NO
Stuck Archiver NO
Datafile Write Errors YES
Oracle Error Conditions:
(none)
DGMGRL>
Check that in this case, I set the threshold for fast-start failover as 240 seconds just to have more time to show the logs. But be aware that this parameter defines the time that your system waits/freeze until proceeding with the failover in case of system isolation or lost the primary.
Here, to simulate side isolation and same behavior for the first article, I shutdown the network from standby (that talk with primary database), for the Master observer (just network that talks with primary database), and for others observers the network for standby communication. The image below reflects this:
After that, the log from Broker in the primary start to report a lot of information and I will discuss below. You can click here to check the full text for this. From this log you can see that the primary detected that lost communication with standby at 20:14:06.504 and in 4 minutes (240 seconds) will trigger the failover. But the most important part is marked below:
2019-05-05 20:14:36.506 LGWR: still awaiting FSFO ack after 30 seconds 2019-05-05 20:14:41.968 DMON: Creating process FSFP 2019-05-05 20:14:44.976 FSFP: Process started 2019-05-05 20:14:44.976 FSFP: The ping from current master observer (No. 1) to primary database timed out. 2019-05-05 20:14:44.976 FSFP: Preparing to switch master observer from observer 1 to observer 2 2019-05-05 20:14:44.976 FSFP: FSFO SetState(st=43 "SET SWOB INPRG", fl=0x0 "", ob=0x0, tgt=0, v=0) 2019-05-05 20:14:44.976 DMON: FSFP successfully started 2019-05-05 20:14:44.977 FSFP: persisting FSFO state flags=0x10040001, version=128, enver=123,target=2, lad=, obid=0x32cc2adc (852241116), threshold=240, laglim=30, obslim=30 2019-05-05 20:14:44.979 FSFP: Data Guard Broker initiated a master observer switch since the current master observer cannot reach the primary database 2019-05-05 20:14:44.980 FSFP: NET Alias translated: (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = dbstb_dg)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = orcls) (UR=A))) 2019-05-05 20:14:44.980 FSFP: Net link using RFIUPI_DB_CDESC, site=2, inst=0 2019-05-05 20:14:44.981 FSFP: Connect to member orcls using (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=dbstb_dg)(PORT=1521))(CONNECT_DATA=(SERVER=DEDICATED)(UR=A)(SERVICE_NAME=orcls_DGB))) 2019-05-05 20:14:44.981 FSFP: 0 x 10 seconds network retry READY 2019-05-05 20:14:51.506 LGWR: still awaiting FSFO ack after 45 seconds 2019-05-05 20:14:55.120 FSFP: Failed to connect to remote database orcls. Error is ORA-12543 2019-05-05 20:14:55.120 FSFP: FSFO SetState(st=44 "CLR SWOB INPRG", fl=0x0 "", ob=0x0, tgt=0, v=0) 2019-05-05 20:14:55.120 FSFP: persisting FSFO state flags=0x40001, version=128, enver=123,target=2, lad=, obid=0x32cc2adc (852241116), threshold=240, laglim=30, obslim=30 2019-05-05 20:15:06.507 LGWR: still awaiting FSFO ack after 60 seconds 2019-05-05 20:15:10.124 FSFP: The ping from current master observer (No. 1) to primary database timed out. 2019-05-05 20:15:10.124 FSFP: Preparing to switch master observer from observer 1 to observer 2 2019-05-05 20:15:10.124 FSFP: FSFO SetState(st=43 "SET SWOB INPRG", fl=0x0 "", ob=0x0, tgt=0, v=0) 2019-05-05 20:15:10.124 FSFP: persisting FSFO state flags=0x10040001, version=128, enver=123,target=2, lad=, obid=0x32cc2adc (852241116), threshold=240, laglim=30, obslim=30 2019-05-05 20:15:10.128 FSFP: Data Guard Broker initiated a master observer switch since the current master observer cannot reach the primary database 2019-05-05 20:15:10.128 FSFP: NET Alias translated: (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = dbstb_dg)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = orcls) (UR=A))) 2019-05-05 20:15:10.128 FSFP: Net link using RFIUPI_DB_CDESC, site=2, inst=0 2019-05-05 20:15:10.128 FSFP: Connect to member orcls using (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=dbstb_dg)(PORT=1521))(CONNECT_DATA=(SERVER=DEDICATED)(UR=A)(SERVICE_NAME=orcls_DGB))) 2019-05-05 20:15:10.128 FSFP: 0 x 10 seconds network retry READY 2019-05-05 20:15:14.979 DMON: A Fast-Start Failover target switch is necessary because the primary cannot reach the Fast-Start Failover target standby database 2019-05-05 20:15:14.980 DMON: A target switch was not attempted because the observer has not pinging primary recently. 2019-05-05 20:15:21.246 FSFP: Failed to connect to remote database orcls. Error is ORA-12543 2019-05-05 20:15:21.247 FSFP: FSFO SetState(st=44 "CLR SWOB INPRG", fl=0x0 "", ob=0x0, tgt=0, v=0) 2019-05-05 20:15:21.247 FSFP: persisting FSFO state flags=0x40001, version=128, enver=123,target=2, lad=, obid=0x32cc2adc (852241116), threshold=240, laglim=30, obslim=30
Above you can see that the broker in the primary detected that the master observer is down and tries to realize the switch to another observer. Unfortunately, since it was not possible to connect with the standby database was impossible to change it. Look the event “SET SWOB INPRG” was triggered but the “CLR SWOB INPRG” was impossible because “Failed to connect to remote database orcls. Error is ORA-12543”. If you compare with the log from the previous article (when I changed the master observer manually) here we don’t see the “SET OBID” and even “OBSERVED” events.
So, basically, because the standby database was incommunicable, the primary database can’t swap the master observer (even if receive connection with them). This behavior does not change even if you set big values for “FastStartFailoverThreshold”, “OperationTimeout”, “CommunicationTimeout” parameters.
Quorum
In one scenario for DG with Fast-Start Failover enabled you can hit a shutdown from your healthy primary database because it thinks that it is isolated when lost communication from standby and observer. Even when you add multiple observers the behavior does not change.
By the actual design for DG, this is 100% correct, it is impossible for each side to know if it is isolated or no. The primary, when lost the connection from Master Observer and Standby, shutdown because can’t guarantee the transactions. And the standby (if alive and have the connection for the Master Observer) failover to be the next primary. The problem is that even using multiple observers, where you can have odd votes, you still face isolation if the minimal part (standby + master observer) vote itself (even if it is isolated). As discussed in the first article, where you put your observer it is very important, but you need to check the pros and cons of your decision.
Going deeper, when you use the Fast-Start Failover your DG starts to operate in sync (even in Max Availability), and in the first sign of communication failure the primary database freeze and doesn’t accept more transactions. No records are stored, and this is why, even with multiple observers, the primary can’t switch to another one. The database itself is blocked to store this change.
One option that can improve this gap is Broker starts to use Quorum (or voting system) to control if it is ok to proceed with the failover or no. In the scenario that I showed before, where the primary still has a connection from the other two observers, the shutdown of the healthy primary does not occur because they have more votes/connections from observers (2) compared with standby (that have just one). Unfortunately, there is not a perfect solution, if one outage occurs on the primary side, and you lost connection with most part of observers, the standby can’t failover because you don’t know if you have votes to do that or no.
This can be a future and additional option for Fast-Start Failover environments. But the key and fundamental part are still there, even quorum will not work correctly if you still put all the observers in just one side. And become even more critical when, now, you can have hybrid clouds with one for databases and other for applications.
The idea about writing these articles was to show the problem and try to fill the gap about the place to put your observer. There is no clear doc to search the “pros and cons” for each side option. Unfortunately, even with the new features, still exists a gap that needs to be covered to improve the reliability for some scenarios. There is no perfect solution, but it is important to know what you can do to reach MAA at the highest level.
Disclaimer: “The postings on this site are my own and don’t necessarily represent my actual employer positions, strategies or opinions. The information here was edited to be useful for general purpose, specific data and identifications were removed to allow reach the generic audience and to be useful for community. Post protected by copyright.”