Metrics for Exadata deliver to you one way to deeply see, and understand, what it is happening for Exadata Storage Server and Exadata Software. Understand it is fundamental to identify and solve problems that can be hidden (or even unsee) from the database side. In this post, I will explain details about these metrics and what you can do using them.
My last article about Exadata Storage Server metrics was about one example of how to use them to identify problems that do not appear in the database side. In that post, I showed how I used the metric DB_FC_IO_BY_SEC to identify bad queries.
The point for Exadata (that I made in that article), is that most of the time, Exadata is so powerful that bad statements are handled without a problem because of the features that exist (flashcache, smartio, and others). But another point is that usually, Exadata is a high consolidated environment, where you “consolidate” a lot of databases and it is normal that some of them have different workloads and needs. Using metrics can help you to do a fine tune of your environment, but besides that, it delivers to you one way to check and control everything that’s happening.
In this post, I will not explain each metric one by one, but guide you to understand metrics and some interesting and important details about them.
Understanding Metrics
Metrics for Exadata are values extract directly from hardware or directly from storage server software. Values from “IOPS from each disk”, or “MB/s read by SMARTIO” are an example of what you can discover. Directly from the docs:
“Metrics are recorded observations of important run-time properties or internal instrumentation values of the storage cell and its components, such as cell disks or grid disks. Metrics are a series of measurements that are computed and retained in memory for an interval of time, and stored on a disk for a more permanent history.”
To check the definition for Exadata metrics, and all metrics available the best place it the official Exadata User Guide, chapter 6. You can see the definition for all metrics and other important information. I really recommend that you read it to be aware of what you can extract from the metrics.
When reading metrics, you can read the current values (from the last minute), or from history view. From the historic list, values are for each minute from the last 7 days. So, with metrics, you cover 24×7 for each minute during the last 7 days. So, a good source of information to help you. And most important, they are individual and read from each storage server.
Reading metrics
To read metrics you can connect directly in the storage server and with the cellcli use the “list metriccurrent” or “list metrichistory” commands to read it:
[root@exacellsrvx-01 ~]# cellcli
CellCLI: Release 18.1.9.0.0 - Production on Sun Dec 08 15:01:42 BRST 2019
Copyright (c) 2007, 2016, Oracle and/or its affiliates. All rights reserved.
CellCLI> list metriccurrent
CD_BY_FC_DIRTY CD_00_exacellsrvx-01 0.000 MB
…
…
SIO_IO_WR_RQ_FC_SEC SMARTIO 0.000 IO/sec
SIO_IO_WR_RQ_HD SMARTIO 2,768,097 IO requests
SIO_IO_WR_RQ_HD_SEC SMARTIO 0.000 IO/sec
CellCLI>
Since it is based in the list command you can detail it, restrict with where, or change the attributes to display it:
CellCLI> list metriccurrent where name = 'FL_IO_DB_BY_W_SEC' detail
name: FL_IO_DB_BY_W_SEC
alertState: normal
collectionTime: 2019-12-08T15:10:14-02:00
metricObjectName: FLASHLOG
metricType: Instantaneous
metricValue: 0.189 MB/sec
objectType: FLASHLOG
CellCLI> list metriccurrent where name = 'FL_IO_DB_BY_W_SEC' attributes name, metricvalue, collectionTime
FL_IO_DB_BY_W_SEC 0.133 MB/sec 2019-12-08T15:11:14-02:00
CellCLI>
You can query the metric for each one of the attributes. Like all metrics for IORM or all metrics for that have FC in the name. If you want to query values in the past, you need to use list metrichistory:
CellCLI> list metrichistory where name = 'FL_IO_DB_BY_W_SEC' and collectionTime = '2019-12-08T15:21:14-02:00' attributes name, metricvalue, collectionTime
FL_IO_DB_BY_W_SEC 0.196 MB/sec 2019-12-08T15:21:14-02:00
CellCLI>
Metric types
There are three types of metrics: Instantaneous (value reflect the moment when was read), Rate (values computed based in the period of time), Cumulative (values since you started storage server from the last time).
All the metrics type Rate, usually are expressed by second. This means that Exadata counted the values from the last minute and divided it by seconds. So, the *_SEC means the average based at the last minute.
One important detail is that some have the “small” and “large” metrics. This means that if your request from the database needs more than 128KB the values are marked as large *LG*, otherwise, as small *SM*.
Using metrics
To understand metrics for Exadata it is important to know the limits for your hardware, and for Exadata the good (and quick way) is the datasheet. Using the X8M datasheet as an example we can see that the max GB/s per second for each storage server is around 1.78 (25GB/s for full rack divided by 14 storage – as for example). Understand these numbers are important, I recommend you to read the datasheet and understand them.
Since every storage computes each metric in the separate way you need to query each one to have the big picture. But this does not mean that some metrics need to be analyzed globally, instead of per each server. I usually divide Exadata metrics in two ways, Isolated and Per Database.
Isolated Metrics
I consider isolated metrics that are important to check for each server. They express values that are important to check isolated per each storage server. Some metrics that I like to check isolated:
- CL_CPUT: The cell CPU utilization.
- CL_MEMUT: The percentage of total physical memory used.
- N_HCA_MB_RCV_SEC: The number of megabytes received by the InfiniBand interfaces per second
- N_HCA_MB_TRANS_SEC: The number of megabytes transmitted by the InfiniBand interfaces per second.
- CD_IO_BY_R_LG_SEC: The rate which is the number of megabytes read in large blocks per second from a cell disk.
- CD_IO_BY_R_SM_SEC: The rate which is the number of megabytes read in small blocks per second from a cell disk.
- CD_IO_BY_W_LG_SEC: The rate which is the number of megabytes written in large blocks per second on a cell disk.
- CD_IO_BY_W_SM_SEC: The rate which is the number of megabytes written in small blocks per second on a cell disk.
- CD_IO_RQ_R_LG_SEC: The rate which is the number of requests to read large blocks per second from a cell disk.
- CD_IO_RQ_R_SM_SEC: The rate which is the number of requests to read small blocks per second from a cell disk.
- CD_IO_RQ_W_LG_SEC: The rate which is the number of requests to write large blocks per second to a cell disk.
- CD_IO_RQ_W_SM_SEC: The rate which is the number of requests to write small blocks per second to a cell disk.
- CD_IO_TM_R_LG_RQ: The rate which is the average latency of reading large blocks per request to a cell disk.
- CD_IO_TM_R_SM_RQ: The rate which is the average latency of reading small blocks per request from a cell disk.
- CD_IO_TM_W_LG_RQ: The rate which is the average latency of writing large blocks per request to a cell disk.
- CD_IO_TM_W_SM_RQ: The rate which is the average latency of writing small blocks per request to a cell disk.
- CD_IO_UTIL: The percentage of device utilization for the cell disk.
- FC_BY_ALLOCATED: The number of megabytes allocated in flash cache.
- FC_BY_USED: The number of megabytes used in flash cache.
- FC_BY_DIRTY: The number of megabytes in flash cache that are not synchronized to the grid disks.
- FC_IO_BY_R_SEC: The number of megabytes read per second from flash cache.
- FC_IO_BY_R_SKIP_SEC: The number of megabytes read from disks per second for I/O requests that bypass flash cache. Read I/O requests that bypass flash cache go directly to disks. These requests do not populate flash cache after reading the requested data.
- FC_IO_BY_R_MISS_SEC: The number of megabytes read from disks per second because not all requested data was in flash cache.
- FC_IO_BY_W_SEC: The number of megabytes per second written to flash cache.
- FC_IO_BY_W_SKIP_SEC: The number of megabytes written to disk per second for I/O requests that bypass flash cache.
- FC_IO_RQ_R_SEC: The number of read I/O requests satisfied per second from flash cache.
- FC_IO_RQ_W_SEC: The number of I/O requests per second which resulted in flash cache being populated with data.
- FC_IO_RQ_R_SKIP_SEC: The number of read I/O requests per second that bypass flash cache. Read I/O requests that bypass flash cache go directly to disks
- FC_IO_RQ_W_SKIP_SEC: The number of write I/O requests per second that bypass flash cache.
- FL_IO_DB_BY_W_SEC: The number of megabytes written per second were written to hard disk by Exadata Smart Flash Log
- FL_IO_FL_BY_W_SEC: The number of megabytes written per second were written to flash by Exadata Smart Flash Log.
- FL_IO_TM_W_RQ: Average redo log write latency. It includes write I/O latency only.
- FL_RQ_TM_W_RQ: Average redo log write request latency.
- FL_IO_W_SKIP_BUSY: The number of redo writes during the last minute that could not be serviced by Exadata Smart Flash Log.
- N_MB_RECEIVED_SEC: The rate which is the number of megabytes received per second from a particular host.
- N_MB_SENT_SEC: The rate which is the number of megabytes received per second from a particular host.
- SIO_IO_EL_OF_SEC: The number of megabytes per second eligible for offload by smart I/O.
- SIO_IO_OF_RE_SEC: The number of interconnect megabytes per second returned by smart I/O.
- SIO_IO_RD_FC_SEC: The number of megabytes per second read from flash cache by smart I/O.
- SIO_IO_RD_HD_SEC: The number of megabytes per second read from hard disk by smart I/O.
- SIO_IO_RD_RQ_FC_SEC: The number of read I/O requests per second from flash cache by smart I/O.
- SIO_IO_RD_FC_HD_SEC: The number of read I/O requests per second from hard disk by smart I/O.
- SIO_IO_WR_FC_SEC: The number of megabytes per second of flash cache population writes by smart I/O.
- SIO_IO_SI_SV_SEC: The number of megabytes per second saved by the storage index.
With these metrics you can discover, by example, in each server:
- Percentage of CPU and memory utilization.
- GB/s sent by Smart I/O to one database server. And if you compare with the ingest that came from the database you can see percentage safe by smartio.
- The number of flashcache reads that was redirected to disk because the data was not there. Here if you see increase the value tread, maybe you have fixed (or have a lot of data) in flash cache and your queries are demanding other tables.
- For celldisk (CD*) metrics it is important to divide by metricObjectName attribute to identify the read from Disks and from Flash. There is no direct metrics for FD*, they are present (at storage level) as a celldisk, but they have different throughputs values. This is true for EF too that just have flash.
- For flashcache directly, you can check the allocated values (usually 100%), but also the “dirty” usage when data it does not sync (between flash and disks), this can mean a lot of writes for your database, bad query design, or high pressure between consolidating databases (maybe you can disable for one category/database trough IORM).
- From smartscan you can check the MB/s read from flashcache or disk to offload your query. Or even check MB/s that was saved by storage index.
So, as you can see there is a lot of information that you can extract from storage server. I prefer to read these separately (per storage) because if I consider globally (smartio or flascache as an example), I don’t have a correct representation of what it is happening under the hood. Maybe, a good value from one storage can hide a bad from another when I calculate the averages.
The idea for these metrics is to provide one way to see Exadata storage software overview. The amount of data that it is reading from hardware (CD_* metrics) and how it is used by the features. You can see how was safe by storage index of smarscan as an example, or see if the flashcache is correct populated (and not dirty). And even help to identify some queries that may are bypassing the flashache or not using smartio.
Database Metrics
The concept of global metrics does not exist directly in the Exadata, you still need to read separately from each storage server. But I recommend that check it globally, doing the sum for values from each storage server to analyze it. One example it the IOPS (or MB/s) for database, you usually want to know the value for the entire Exadata and not for each server.
In the list, I will put just for database, but you have the same for PDB, Consumer Groups, and from Categories. Remember that for IORM the hierarchy is first Categories and after Databases when creating the plans.
- DB_FC_BY_ALLOCATED: The number of megabytes allocated in flash cache for this database.
- DB_FC_IO_BY_SEC: The number of megabytes of I/O per second for this database to flash cache.
- DB_FC_IO_RQ_LG_SEC: The number of large I/O requests issued by a database to flash cache per second.
- DB_FC_IO_RQ_SM_SEC: The number of small I/O requests issued by a database to flash cache per second.
- DB_FL_IO_BY_SEC: The number of megabytes written per second to Exadata Smart Flash Log.
- DB_FL_IO_RQ_SEC: The number of I/O requests per second issued to Exadata Smart Flash Log.
- DB_IO_BY_SEC: The number of megabytes of I/O per second for this database to hard disks.
- DB_IO_LOAD: The average I/O load from this database for hard disks. For a description of I/O load, see CD_IO_LOAD.
- DB_IO_RQ_LG_SEC: The rate of large I/O requests issued to hard disks by a database per second over the past minute.
- DB_IO_RQ_SM_SEC: The rate of small I/O requests issued to hard disks by a database per second over the past minute.
- DB_IO_TM_LG_RQ: The rate which is the average latency of reading or writing large blocks per request by a database from hard disks.
- DB_IO_TM_SM_RQ: The rate which is the average latency of reading or writing small blocks per request by a database from hard disks.
- DB_IO_UTIL_LG: The percentage of hard disk resources utilized by large requests from this database.
- DB_IO_UTIL_SM: The percentage of hard disk resources utilized by small requests from this database.
- DB_IO_WT_LG_RQ: The average IORM wait time per request for large I/O requests issued to hard disks by a database.
- DB_IO_WT_SM_RQ: The average IORM wait time per request for small I/O requests issued to hard disks by a database.
With these metrics you can see how the database/pdb/cg/ct are using the Exadata. As an example, you can check the MB/s (or IOPS) read from flashcache by seconds. And if you compare with CD_* as an example, you can discover which database is using more it. The same can be done by flashlog.
What you can discover
With metrics you can discover a lot of things that are hidden when you just look from the database side (AWR as an example). And it is more critical when you have a consolidated environment in your Exadata. You can compare values from different databases and have insights from something that is not correct (as my example from the previous post).
Here I will show you another example. Again, all the values I collected using my script that you can check in my post at OTN. This script connects in each storage server and retrieves the values from the last 10 minutes. After that I stored, I made the average value for the minutes reported. This means that every point listed below are the average values computed for every 10 minutes.
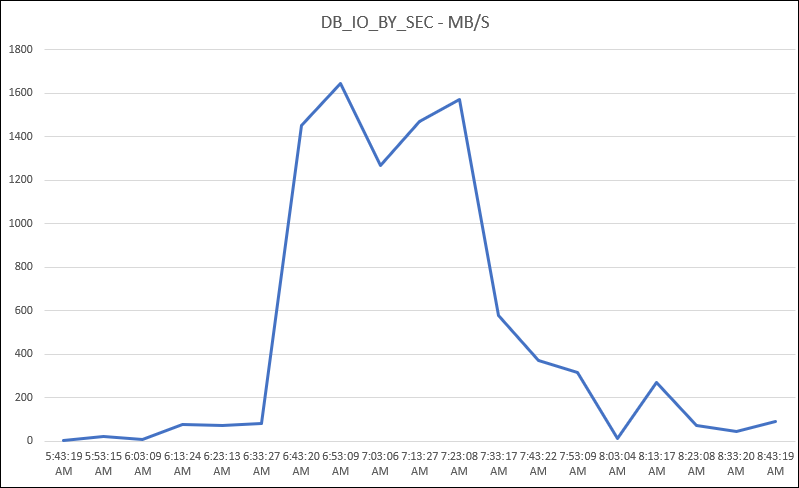
Look above. This graph represents the values from DB_IO_BY_SEC metric. As you can see, the database reached around 1.6 to 1.7GB/s of disk usage. And if you remember for Exadata datasheet, this means that this database used almost everything from disk capacity/throughput from Exadata storage. This can be confirmed by:
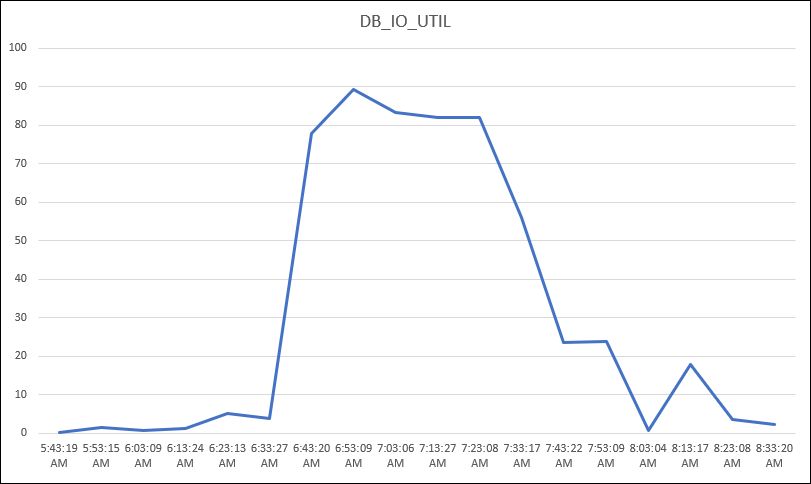
As you can see, the average was around 85 to 90 percent of IO/Utilization for this database. But if I look at the values for each minute, I can see some high usage around 95%.
And as you can image, other databases started to see wait time for the same moment:
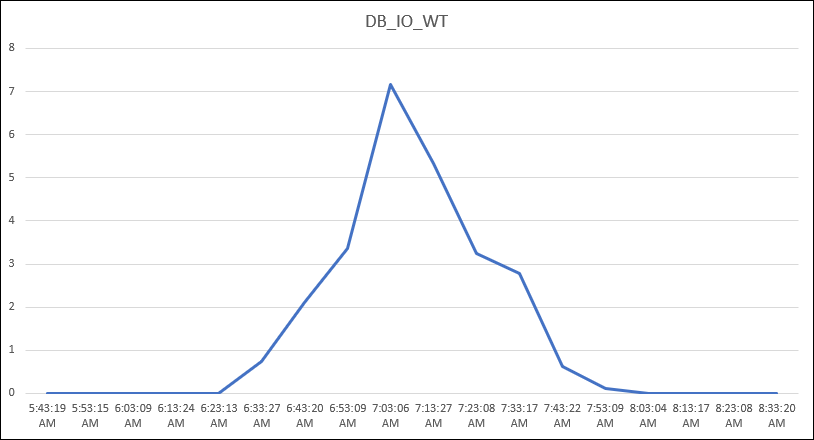
If you compare the three graphs at the same time, you can see that when one database started to use a lot from the storage server (around the max throughput from hardware), another database started to see more wait time for each request. The value below is expressed in ms/r (milliseconds per request).
This is one example of what you can discover using metrics. In this case specifically, the analyses started because one application DBA Team reported that started to notice some slow queries during the morning. But the application changed nothing in the previous 4 months and the AWR and tuning their queries helped nothing. Using the metric was discovered that another database deployed a new version with bad SQL. But looking from this database, everything appears normal.
How to read
If you want to read metrics the best way if trough cellcli, but sometimes you don’t need it of you can’t. You can use the Enterprise Manager/Cloud Control to check some information, but you don’t have all the metrics available, but can use the Exadata plugin to check IOPS and MB/s.
Still, at EM/CC you can try to check the KPI for Storage server and write some queries direct to EM/CC database. Oracle has a good reference about this procedure in this PDF: https://www.oracle.com/technetwork/database/availability/exadata-storage-server-kpis-2855362.pdf
You can still use the Oracle Management Cloud for Exadata to help you to identify bottlenecks in your environment. You can use some IA and Oracle expertise to identify trends easier and be more proactive than reactive https://cloudcustomerconnect.oracle.com/files/32e7361eed/OMC_For_EXADATA_whitepaper_v28.pdf or this blog post from Oracle.
Another way is writing/use one script to integrate with your monitoring tool. You can use my script as a guide and adapt it to your needs. The script can be checked in my post at Oracle OTN (Portuguese Version, Spanish Version, unfortunately, there is no English version. Was sent to be published, but never was – I don’t know why), the version published read all metrics and output it in one line. You can use it to insert it into one database or save it in one file as you desire.
Insights
The idea for metric analysis is to check it and have insights about what can be wrong. Sometimes it is easy to identify (like the example before), but other times you need to dig in a lot of metrics to find the problem (smartio, flashcache, dirty cache, etc).
But unfortunately, to understand metric you need to truly understand Exadata. It is more than a simple knowledge of the hardware or how to patch the Exadata. You need to understand the limits for your machine (datasheet can help), database tuning (to understand a bad query plan), and where to search (which metric use). You need to use this together to have the insights, and unfortunately, this came just with day-to-day usage/practice.
The idea for this post was to provide you a guide, or even a shortcut, to understand the Exadata metric and do more. I did not cover every metric, or every detail for each metric, but tried to show you how to read, analyze, and use it to identify problems.
Disclaimer: “The postings on this site are my own and don’t necessarily represent my actual employer positions, strategies or opinions. The information here was edited to be useful for general purpose, specific data and identifications were removed to allow reach the generic audience and to be useful for the community. Post protected by copyright.”
Pingback: Exadata, Missing Metric | Fernando Simon
Excellent Post. Really you’re right.. Its more than one metric and requires intensive performance tuning knowledge as well as logical correlation .
Went thro’ the scripts. Unable to decode the language.. Can you please send me the script via email
Good post on Exadata storage specific metrics at server level. Question: Is it possible to have at metrics at lowest query level ? (assuming Storage server has sql metadata from database nodes). If its possible how do I get those. Thank you in advance for taking a time to read this.
Hi,
Sorry, but I not understood the question, can you clarify it? What is the lowest level that you means? What do you want to search/query?
Pingback: How to understand and capture ExaCLI Metrics - oratrails-aish