Oracle Zero Data Loss Recovery Appliance (ZDLRA) deliver to you the capacity to improve the reliability of your environment in more than one way. You can improve the RPO (Recovery Point Objective) for your databases until you reach zero, zero data loss. And besides that, adding a lot of new cool features (virtual backups, real-time redo, tape and cloud, DG/MAA integration) on the way how you do that your backups (incremental forever), and backup strategy. And again, besides that, improve the MAA at the highest level that you can hit.
But this is just marketing, right? No, really, works pretty well! My history with ZDLRA starts with Oracle Open World 2014 when they released the ZDLRA and I watched the session/presentation. At that moment I figure out how good the solution was. In that moment, hit exactly the problem that I was suffering for databases: deduplication (bad dedup). One year later, in 2015 at OOW I made the presentation for a big project that I coordinate (from definition implementation, and usage) with 2 Sites + 2 ZDLRA + N Exadata’s + Zero RPO and RTO + DG + Replication. And at the end of 2017 moved to a new continent, but still involved with MAA and ZDLRA until today.
This post is just a little start point about ZDLRA, I will do a quick review about some key points but will write about each one (with examples) in several other dedicates posts. I will not cover the bureaucratic steps to build the project like that, POC, scope definition, key turn points, and budget. I will talk technically about ZDLRA.
ZDLRA
ZDLRA is one Engineered System built over Exadata. Contains Exadata Storage and Database nodes, InfiniBand network, SAS drivers (for tape connection). So, a good machine with redundancy components. Look the base config:

But as Exadata, it is not just hardware, it is software too (and a lot of in this case). ZDLRA solve problems in more than one topic, it is not just a backup appliance where you redirect your backups, it is an appliance that provides zero data loss. To do that the key features are:
- Virtual backups: Based on the input backups (incremental) generate a virtual full backup for you.
- Real-time Redo: ZDLRA can be an archive log destination for your database, RPO zero.
- Replication: You can replicate data between ZDLRA’s, eliminating single point of failure.
- Tape integration: ZDLRA used OSB to copy backups to tape.
- Rman: totally compatible with rman commands, and deliver to you rman catalog self-managed.
- Database and MAA integration: fully integrated with MAA environments, including DG.
Since it is built over Exadata, the updates follow the same procedure, IB, Storage, Db’s, and after that ZDLRA software. But in this case, you don’t need to concern about integration or tuning for Exadata, everything is done by Oracle. For Storage, ZDLRA uses two diskgroups: DELTA (to store the backups) and CATALOG (to store the rman catalog tables).
The integration between ZDLRA and your databases are simple. You have an SBT_TAPE library to use and the rman catalog database. The library communicates with ZDLRA appliance and sends the blocks, and the rman catalog store the metadata.
Talking about rman catalog, using ZDLRA you need to use the rman catalog. The catalog database that you connect it is the ZDLRA itself. And the catalog it is managed by ZDLRA software, this means that when you send the backup to ZDLRA, and after process it, the catalog reflect all the new virtual full backups that are available. You don’t need to manage the backups, everything is done by ZDLRA software (delete backup, crosscheck, validation, etc).
Virtual backups
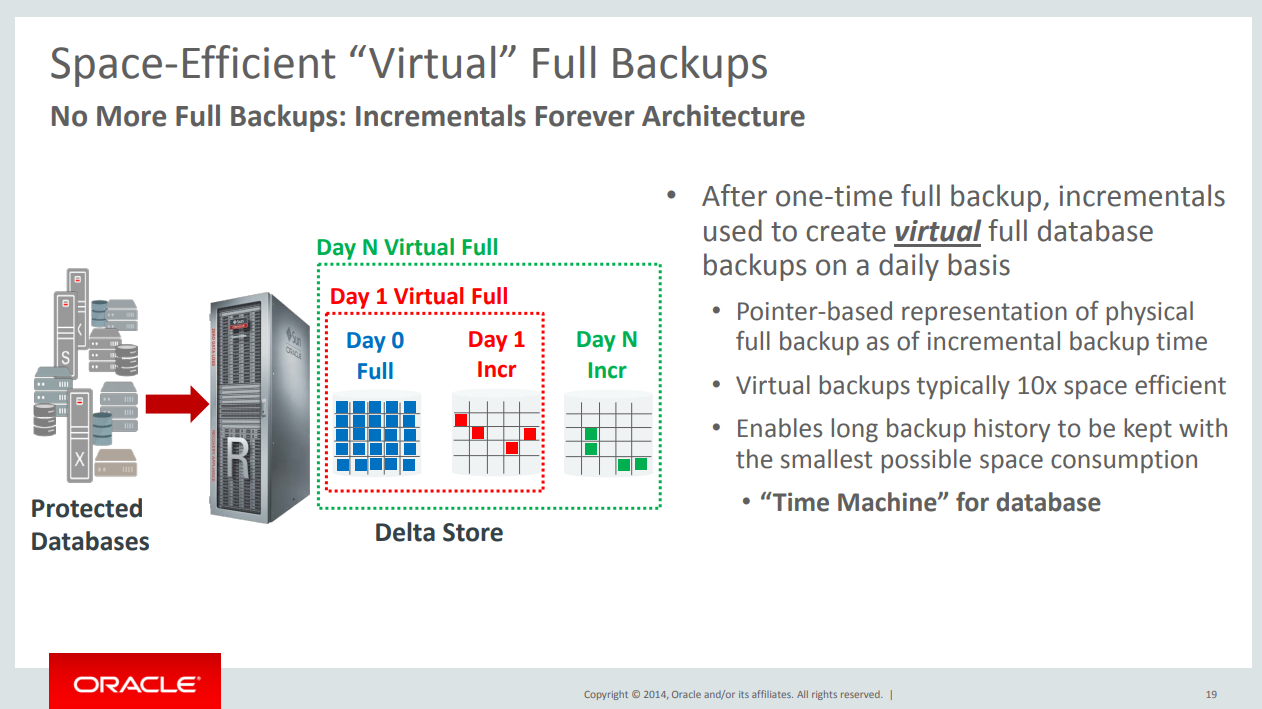
Probably this is the most know feature for ZDLRA. In the most basic description, it “simple” create to you a new backup level 0 just using incremental level 1 backups. The functionality is simple:
- Ingest one first rman level 0 backup.
- Ingest subsequent rman level 1 backup.
- A new “virtual level 0” appears available to you.
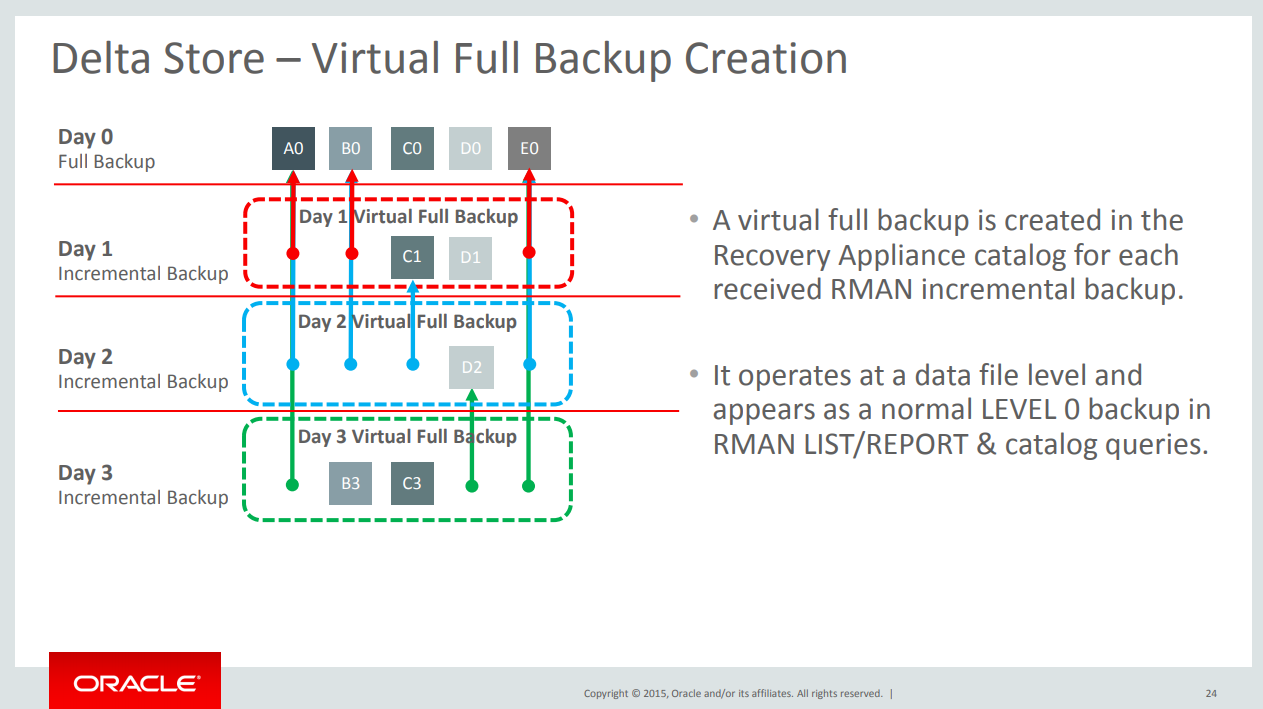
But how it’s work? Basically, ZDLRA open the rman block and read the datafile blocks that are inside of rman block. After that, using the already existed backup (stored inside ZDLRA) for that datafile, generate to you a new level 0 backup. This is called “incremental forever strategy”, where (after first level 0) you just need to do incremental level 1 backups.
If you are thinking about deduplication at this moment, you are almost right. But is really different of other vendors that just index the rman block (by hash, md5, whatever), ZDLRA it is the only one that opens the block and look what it is inside. It’s pick up the content of rman block, the data blocks for each datafile that is inside, and index it.
But why it is better than deduplication? Because it is sensitive to the context. And in this case, it is Oracle context. Work’s better too because can handle every kind of database blocks sizes, any kind of filesperset and chunks that you specify. You don’t need to “black magic” to minimally have good values for dedup, like DataDomain as example: https://community.emc.com/docs/DOC-24118 and https://community.emc.com/docs/DOC-18775. You can argue that DataDomain can do the same, it opens the rman block (just 8k and 16k blocks), but it was done by reverse engineering over the rman block https://www.emc.com/collateral/white-papers/h15389-data-domain-oracle-optimized-deduplication.pdf. But if Oracle changes this pattern? Sometimes can happen that rman read the same datafile blocks (that was not touched by dbwr) but because sga/pga buffers create a different rman block.
A little representation. Think that you work in a Library and I deliver to you (every day) one box with books of an encyclopedia. You store this box but can’t open it to store the books that are inside. You can ignore the box and says that you already have this based on the size, weight, whatever you choose to define if you already have this box. As ZDLRA, you receive the same box, but you open and check if you already have this book in your collection or no. One day I come back and ask you the full encyclopedia and you deliver to me the box with the books. So, what solution do you think that will be better for Oracle backups?
The first is the normal deduplication. Works very well for a lot of blocks types (word, excel, txt) because you “maybe” can open the box. But not so well for binary blocks type (like rman). ZDLRA it is Oracle, and only them have the key to open the box (rman block) and check the content to identify books (the datafile blocks). Even deeper, only them have the ability to rebuild the box (rman block) correctly and deliver to you just the books (datafiles blocks) that you need. Clever no?
There are a lot of other details to cover, I will do in a delicate post about Virtual backups.
Real-Time Redo
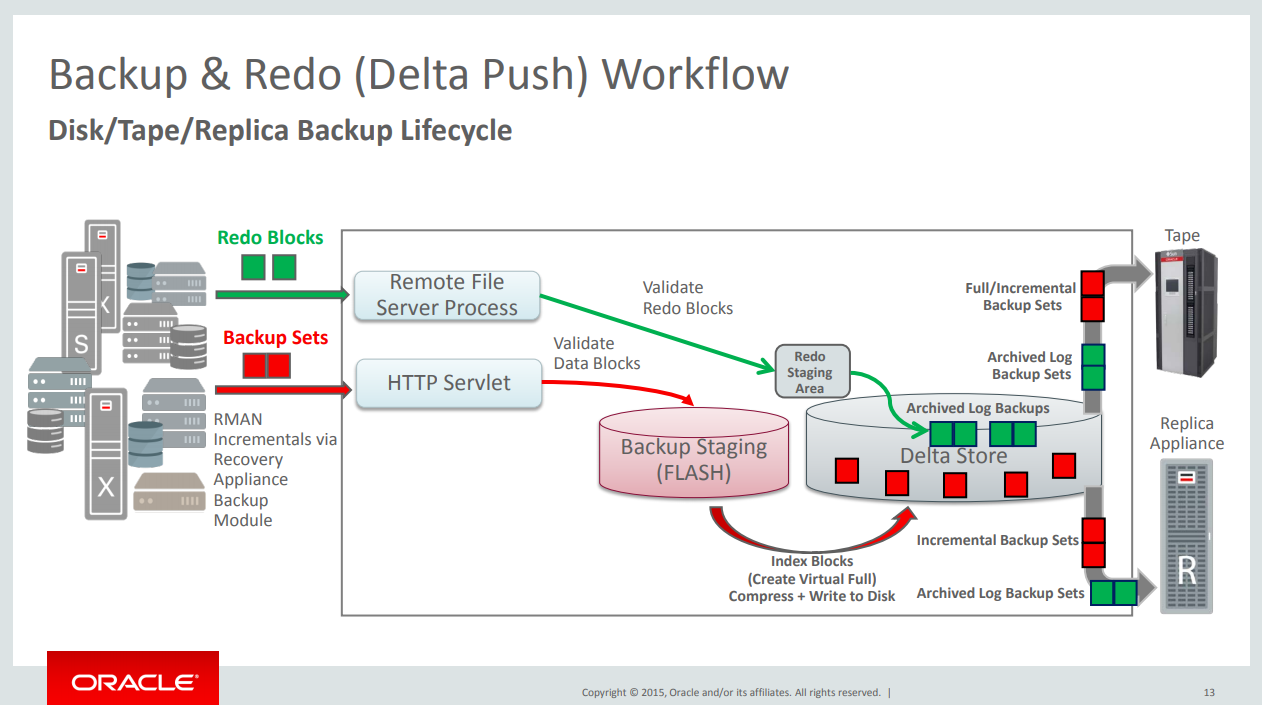
The name from “zero data loss” came from this feature because its guarantee zero RPO for your database. In a simple way, ZDLRA can be archive log destination for your database. It’s work the same way that you do for DG configuration, but more simply because you just need to configure the archive_log_dest.
You can think that it is similar, or you can do the same, using DG Far Sync: https://www.oracle.com/technetwork/database/availability/8395-data-guard-far-sync-1967244.pdf. But here for ZDLRA, you don’t need standby database to protect every transaction.
It is important to say that it is more than just archive log destination because can sync the redo log buffers of your database. Don’t need to wait archive be generated to sync. Can work sync or async, and if your database has an outage (by storage death as an example), ZDLRA generates for you one archivelog. And another thing it is that there is no need to do archivelog backups (if you use real-time redo) because ZDLRA detect the log switch and generate for you (inside catalog) the archivelog.
Besides that, if you use ZDLRA replicated, you can have additional protection sending to another site. I will talk later about that but using replicated ZDLRA’s, you can have RPO zero for DG databases and for non DG protected databases.
Oracle calls Virtual Backups + Real-Time Redo as Delta Push because you just sent to ZDLRA the minimum data needed to be protected. Just the delta difference. This reduces a lot the load over the system, network, avoid reading unusual/repeated data from the source database and inside ZDLRA too.
Replication
ZDLRA can work replicating backups between two ZDLRA’s. This replication is done automatically, using a dedicated network and can be:
- One way: You have the ZDLRA master (called upstream) and the destination (called downstream).
- Bi-Directional: Two ZDLRA’s replicate backups between each self. Both are upstream and downstream.
- Hub-and-Spoke: You have one downstream ZDLRA that receive the backups from more than one upstream.
The detail here is that replication is an additional feature of ZDLRA, even a downstream ZDLRA can protect one site (like standby site), receiving backups from databases as a normal ZDLRA. The downstream ZDLRA does not lock in as just destination from upstream. But since it is a replicated environment, you can restore your backupset from the downstream replica (connected in the upstream ZDLRA).
Based on ZDLRA design, the rman catalog is updated too. This means that after the backup being replicated to the downstream, inside of the catalog automatically appears another copy for your backupset. And you can have different policies between ZDLRA’s. So, in the upstream you can have one policy with retention as 30 days and the downstream have retention as 90 days.
Tape and Cloud integration
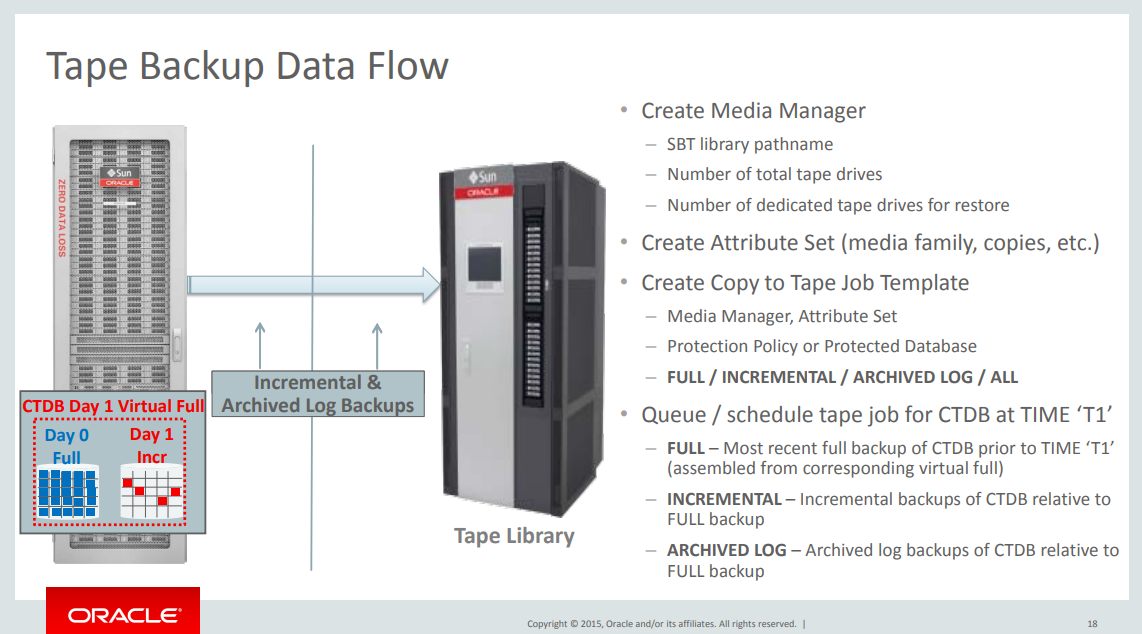
ZDLRA can send backups to media manager (tapes), to do that the recommended way is using the pre-installed OSB (Oracle Secure backup) as media manager library. ZDLRA manage everything, uses the dedicated SAN network to send the backups and manage the tape drivers. Another option is sync ZDLRA with Oracle Cloud object storage.
But you can use third-party software as tape media manager driver, you just need to install the agent in database nodes (of ZDLRA) and configure it as media manager library. It is not trivial, but you can do and integrate your tape library with ZDLRA. In this case, all the communication (copy from ZDLRA to tape) will be done using LAN.
Again, the rman catalog will be automatically managed by ZDLRA. When the backupset it is copied to tape, the copy appears available for restore in your rman catalog.
To manage the tape backups you use the same policies that you use for backups. You can specify the retention period, copies, and more. If you use OSB, ZDLRA will manage everything (free tapes as an example).
For Cloud, the idea is the same. You have one plugin that appears in your ZDLRA as a tape library, and the jobs clones from ZDLRA to cloud (in the same way than tape). But since Oracle Cloud is fully encrypted, you have some steps to manage the key to allow you to integrate the system. This can be one way to have the third site to store your backups outside of your environment.
Rman
As told before, ZDLRA has two main parts: the software itself (that create the virtual backups) and the database. And this database contains the rman catalog that you use to connect. ZDLRA manage automatically the rman catalog database, this means that every backup is sent appears in the catalog. And everything that happens with this backup, the derived virtual full backup, clone to tape, replication, exclusion because retention expiration is reflected automatically in the rman catalog. You don’t need to manage or catalog the backupsets.
But the most important thing is that everything that you already made with rman works 100% with ZDLRA. You don’t need to learn new commands, new backups types. Everything that you need it is “backup incremental level”.
Since ZDLRA will be a central part of your environment, it is important to know how to search for data in the catalog (using SQL). I will show some examples of how to understand the RC_* tables/views that will allow you to create some reports from your backups.
Database and MAA integration
Since it is really linked with MAA family the integration between ZDLRA and databases is quite easy, covering all the points for protection. About protection, not just for backup, but raising the bar for transaction protection to reach zero data loss in any kind of scenario (DG and non DG databases).
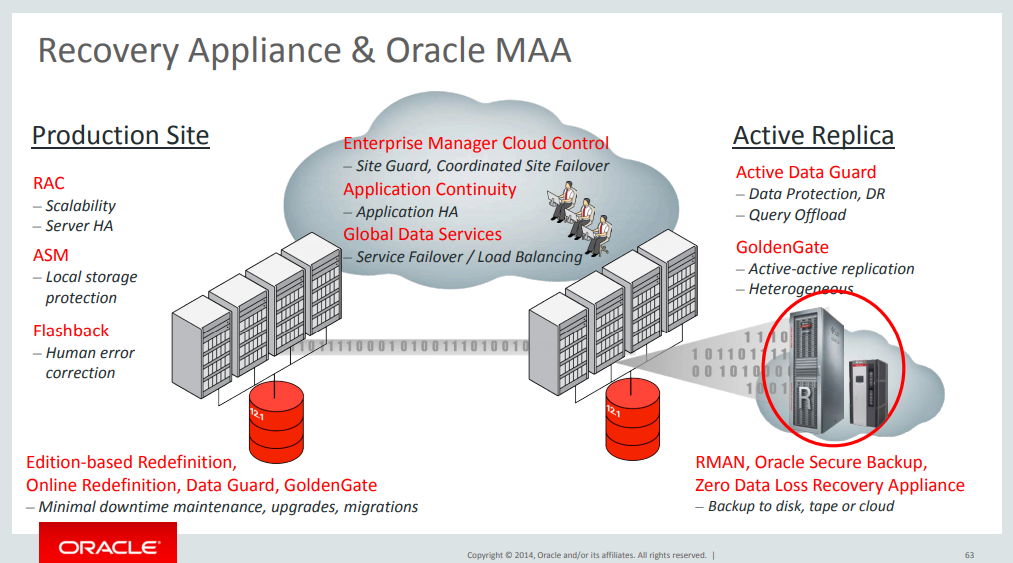
ZDLRA it is not just a backup appliance, it allows you to reach RPO zero even not using DG. But if you are using DG you need to take attention to some details. The idea about DG for MAA team it is that everyone does your job, this means that if you need to protect a database for site outage, DG does that. ZDLRA it is not a full standby database.
Saying that, when you have a full DG environment, you can reach RTO (Recovery Time Objective) as zero too. ZDLRA alone can provide to you just RPO zero but does not help you to have zero downtime (or unavailability). You not loose transactions with RPO zero, but will need some time to recover the database. The only way to have both, RTO and RPO zero is using DG. In this scenario, each database does the backup in ZDLRA that it is in the same site, and the DG does the sync between the sited (for DB with DG).
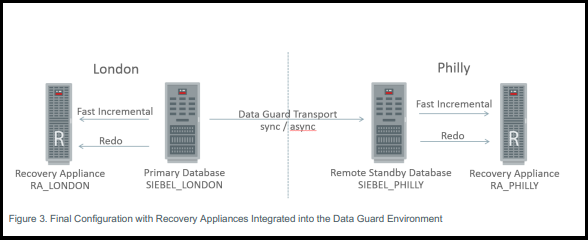
If you have more than one site and want to protect everything the best solution is to have ZDLRA in both sites. You can still have just one ZDLRA and protect everything, but remember that you need to choose one site (or a third one) to put your ZDLRA.
But the good part is that you can mix everything. There are a lot of cases that some databases are not protected by DG. For these, you can use real-time redo to have RPO zero, and replicate to another ZDLRA in another site to avoid the only point of failure.
This raises the bar for MAA because it is the highest level that you can reach in protection. Even if you cut the communication for each site you still have RPO zero because of ZDLRA protection. And if you have a complete site or server failure, the RTO will be zero due to DG.
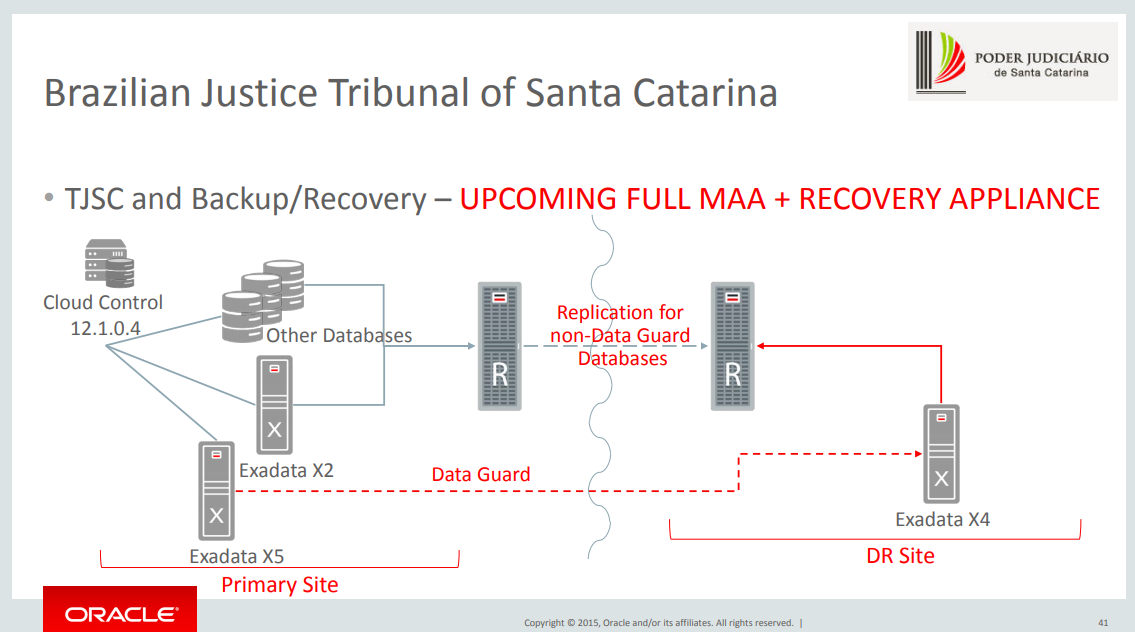
This was the project that I designed and you can see this (was presented in OOW 2015: https://www.oracle.com/technetwork/database/availability/con8830-zdlradeepdive-2811109.pdf).
Conclusion
ZDLRA it is not just a backup appliance, it is more than that. It allows you to reach RPO zero for any kind of environment. And together with DG, you can reach zero RPO and RTO.
But besides that, the ZDLRA software delivers to you a lot of features that help you in daily bases activities. The virtual backups deliver to you a validated level zero backupset for each datafile. You receive a rman catalog self-managed, you don’t need to catalog (or uncatalog) pieces for a clone to tapes, deletion, replications that you do.
And there is no need to learn complex new features, you continue to do the backups in the same way that you do previously. “backup incremental level 1” and just that.
For the next post, I will try to cover feature by feature and a lot of details, virtual backups, real-time redo, dg integration, internal tasks, updates. Stay tuned.
References
All the images and base info for this post came from these links:
https://www.oracle.com/technetwork/database/availability/con8830-zdlradeepdive-2811109.pdf
https://www.oracle.com/technetwork/database/availability/8395-data-guard-far-sync-1967244.pdf
https://docs.oracle.com/cd/E55822_01/AMOGD/E37432-22.pdf
https://docs.oracle.com/cd/E55822_01/AMAGD/E37431-29.pdf
http://www.oracle.com/us/products/engineered-systems/recovery-appliance-twp-2313693.pdf
https://www.oracle.com/technetwork/database/availability/recoveryapplianceperformance-2636208.pdf
https://www.oracle.com/technetwork/database/availability/recovery-appliance-businesscase-2574428.pdf
https://www.oracle.com/technetwork/database/availability/recovery-appliance-data-guard-2767512.pdf
https://www.oracle.com/technetwork/database/features/availability/ow-papers-089200.html
Disclaimer: “The postings on this site are my own and don’t necessarily represent my actual employer positions, strategies or opinions. The information here was edited to be useful for general purpose, specific data and identifications were removed to allow reach the generic audience and to be useful for the community. Post protected by copyright.”
Pingback: How to use ZDLRA and enroll a database | Blog Fernando Simon
Pingback: ZDLRA Internals, Tables and Storage | Blog Fernando Simon
Pingback: ZDLRA Internals, INDEX_BACKUP task in details | Blog Fernando Simon
Pingback: ZDLRA Internals, Virtual Full Backup | Fernando Simon
Pingback: ZDLRA, Multi-site protection - ZERO RPO for Primary and Standby | Fernando Simon
Pingback: ZDLRA, Replication | Fernando Simon
Pingback: ZDLRA Internals, INDEX_BACKUP task in details | Fernando Simon
Dear Sir,
We are planing to schedule a backup to tape from zdlra. We recommended following to the customer.
1. Daily archive backups and Full backup every 15th of month and every month end. (Retention 5 month).
2. Can we give TAG option while taking backup to tape to recognise which backup belongs to which month.
3. OSB is not very user freindly since we are facing lot of issue pushing full backup to tape. Is there any good blogs for scheduling backups to tape
written by you.
Thanks
Rahul
blog of scheduling full backup to tape through OEM.
Thanks
Rauhl