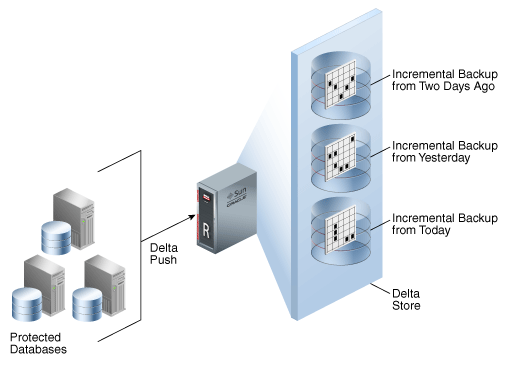
ZDLRA can be used from a small single database environment to big environments where you need protection in more than one site at the same time. At every level, you can use different features of ZDLRA to provide desirable protection. Here I will show how to reach zero RPO for both primary and standby databases. All the steps, doc, and tech parts are covered.
You can check the examples the reference for every scenario int these two papers from the Oracle MAA team: MAA Overview On-Premises and Oracle MAA Reference Architectures. They provide good information on how to prepare to reduce RPO and improve RTO. In resume, the focus is the same, reduce the downtime and data loss in case of a catastrophe (zero RPO, and zero RPO).
Multi-site protection
If you looked both papers before, you saw that to provide good protection is desirable to have an additional site to, at least, send the backups. And if you go higher, for GOLD and PLATINUM environments, you start to have multiple sites synced with data guard. These Critical/Mission-critical environments need to be protected for every kind of catastrophic failure, from disk until complete site outage (some need to follow specific law’s requirements, bank as an example).
And the focus of this post is these big environments. I will show you how to use ZDLRA to protect both sites, reaching zero RPO even for standby databases. And doing that, you can survive for a catastrophic outage (like entire datacenter failure) and still have zero RPO. Going further, you can even have zero RPO if you lose completely on site when using real-time redo for ZDLRA, and this is not written in the docs by the way.
Click here to read more…