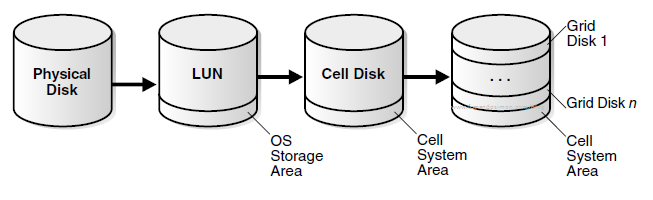
Here I will cover the shrink of ASM diskgroup in Exadata environment running VM’s. The process here is the opposite of what I wrote in the previous post, but have a tricky part that demands attention to avoid errors. The same points that you checked for extending are valid now: number the cells, disks per cell, ASM mirroring, and the VM that you want to change continue to be important, but we have more now. Besides that, the post shows how to verify (and “fix”) if you have something in the ASM internal extent map that can block the shrink.
Shrink ASM Diskgroup and Exadata Grid Disks
Leave a reply