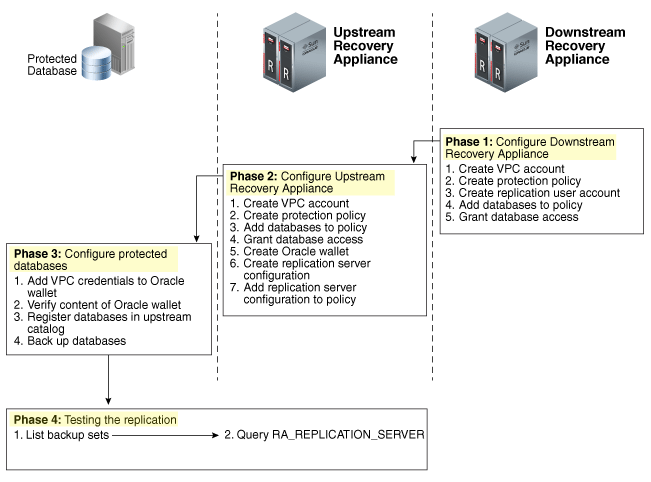
The Oracle Maximum Availability Architecture (MAA) is the correct way to protect your Oracle database environment (and investment). It covers from a simple single instance to Exadata/Engineered Systems RAC and a multi-site database with Data Guard protection. But do you know that to reach the MAA (whatever the architecture level that you are protecting) you need to use ZDLRA?
So, I will start a series of posts to cover the MAA and ZDLRA. Discussing what you need to do (and how) to reach the maximum level of availability as is at the MAA architecture (as defined in the documentation and best practices: Oracle Maximum Availability Architecture (MAA) Blueprints for On-Premises, MAA Best Practices – Oracle Database, and Maximum Availability with Oracle Database 19c).
Why ZDLRA?
The question is why ZDLRA is needed? The point from ZDLRA is that it can (and needed to be used) to protect and reach zero RPO to all architectures. ZDLRA is more (much more) than just a backup appliance, is the core of every MAA design. You can’t reach zero RPO without using it.