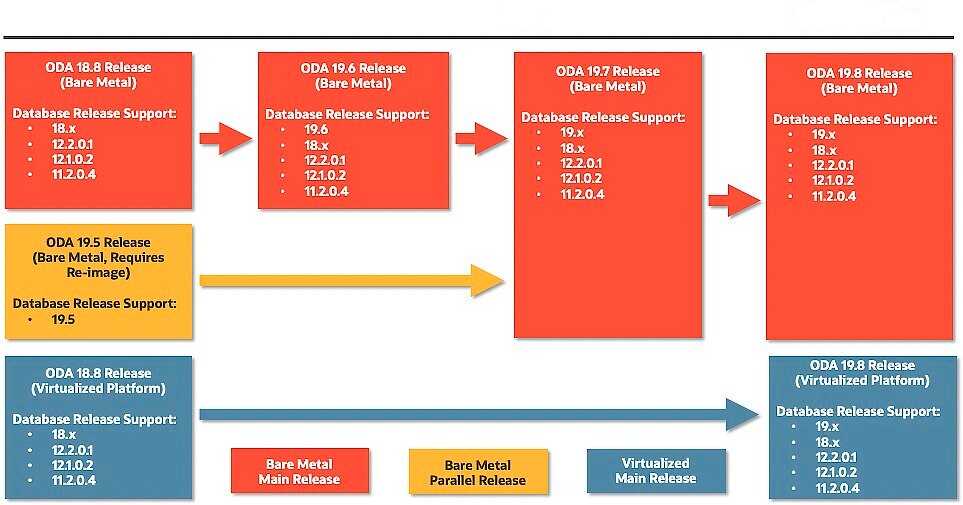
If you search around about how to patch Oracle Database you will find a lot of blog posts teaching how to patch your Oracle Home (OH) (I will not put the list here because it will be enormous – but just follow Mike Dietrich). But most of them write nothing about OCW, how to patch it, or if it is needed to patch OCW. And unfortunately, even Oracle is not clear about that.
Just to complement, recently Liron Amitzi got one issue related to OCW. And if you search more, you will find that Frits Hoogland wrote something about it too. But in the end, need I to concern about OCW? And, what is OCW?
OCW
OCW means Oracle Clusterware, and basically is the core for the Grid Infrastructure, it is everything there. But for OH is important too because if the database needs to communicate with GI Clusterware it uses the OCW binaries/libraries that are at OH (like srvctl, crstctl) to do that. So, if have some kind of bug at this portion of OCW, it needs to be patched.
The point is that the only place that you can find the OCW patch is under the GI RU patch. Look at the readme for last GI RU 19.8.0.0.200714 (Patch 31305339):

And if you look at the readme for DB RU 19.8.0.0.200714 (Patch 31281355) there is no reference to the OCW patch. So, if apply just the DB RU the OCW will not be updated.
And just to remember you that patch 31305087 does not exist alone to be downloaded:
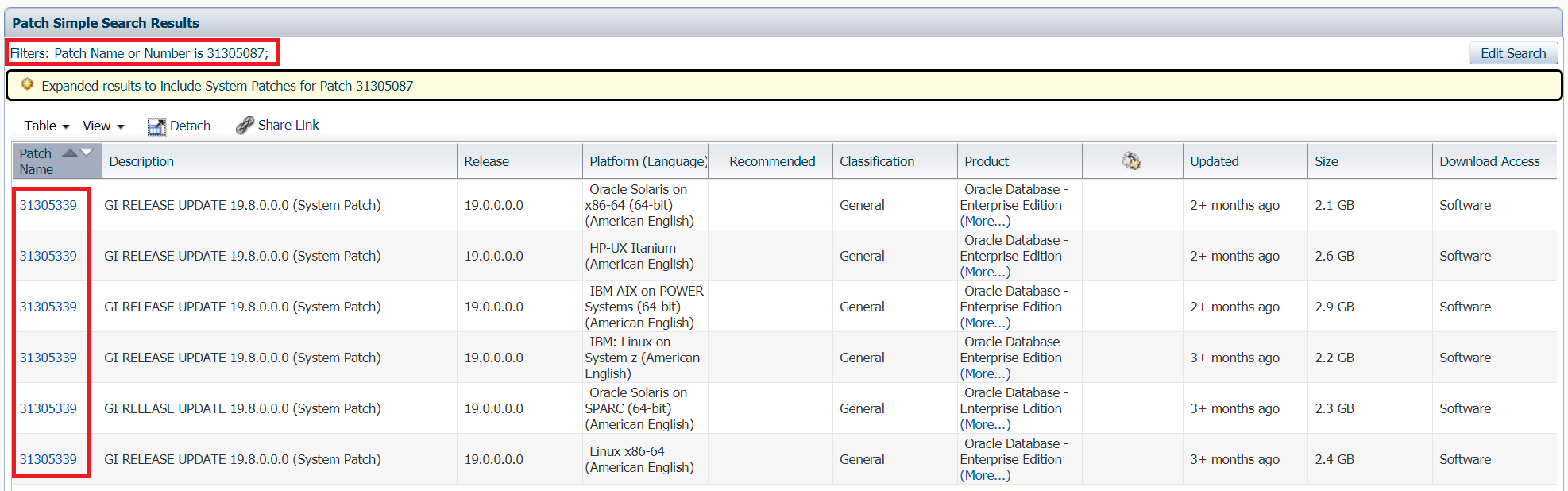
Click here to read more…