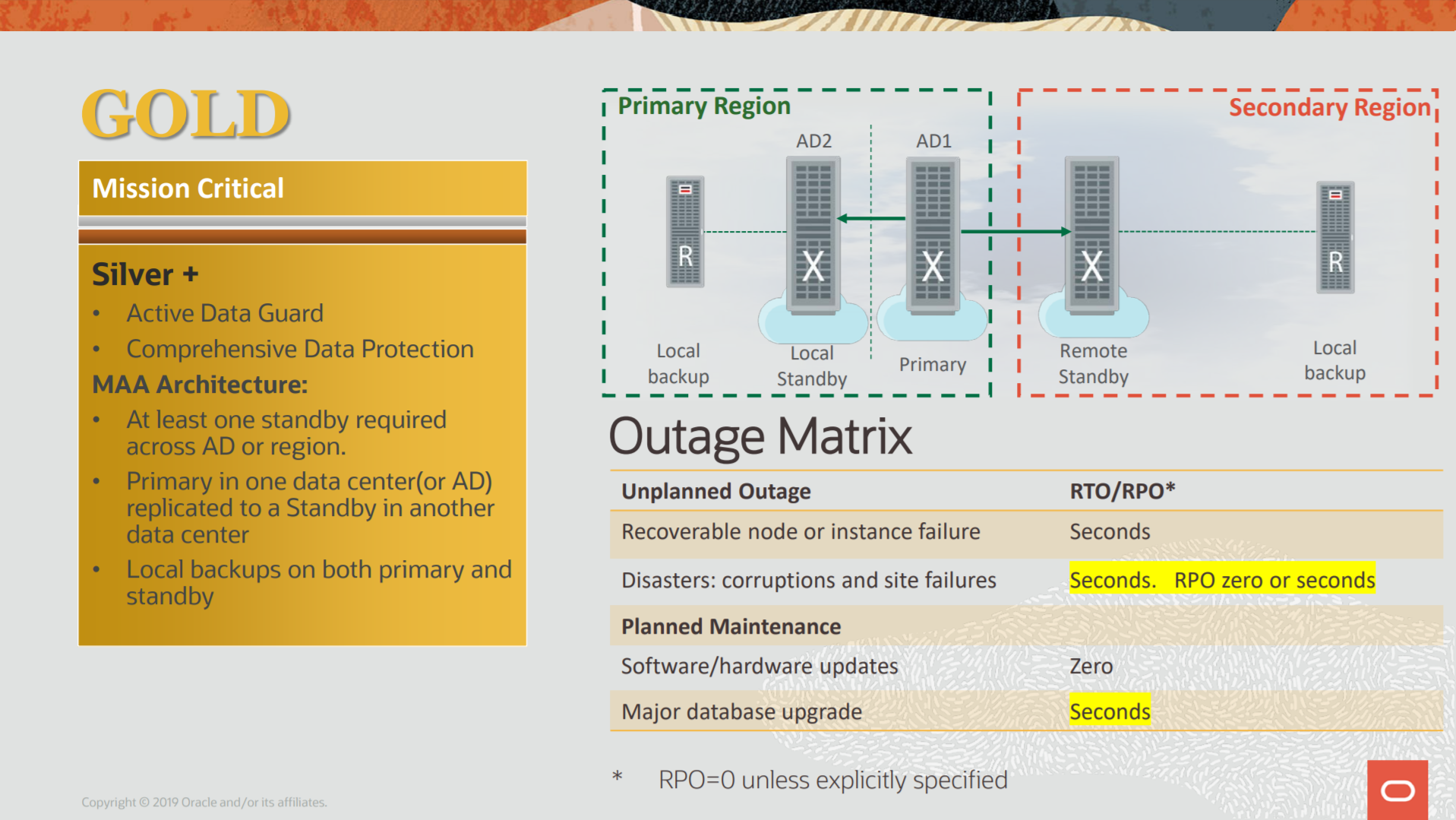
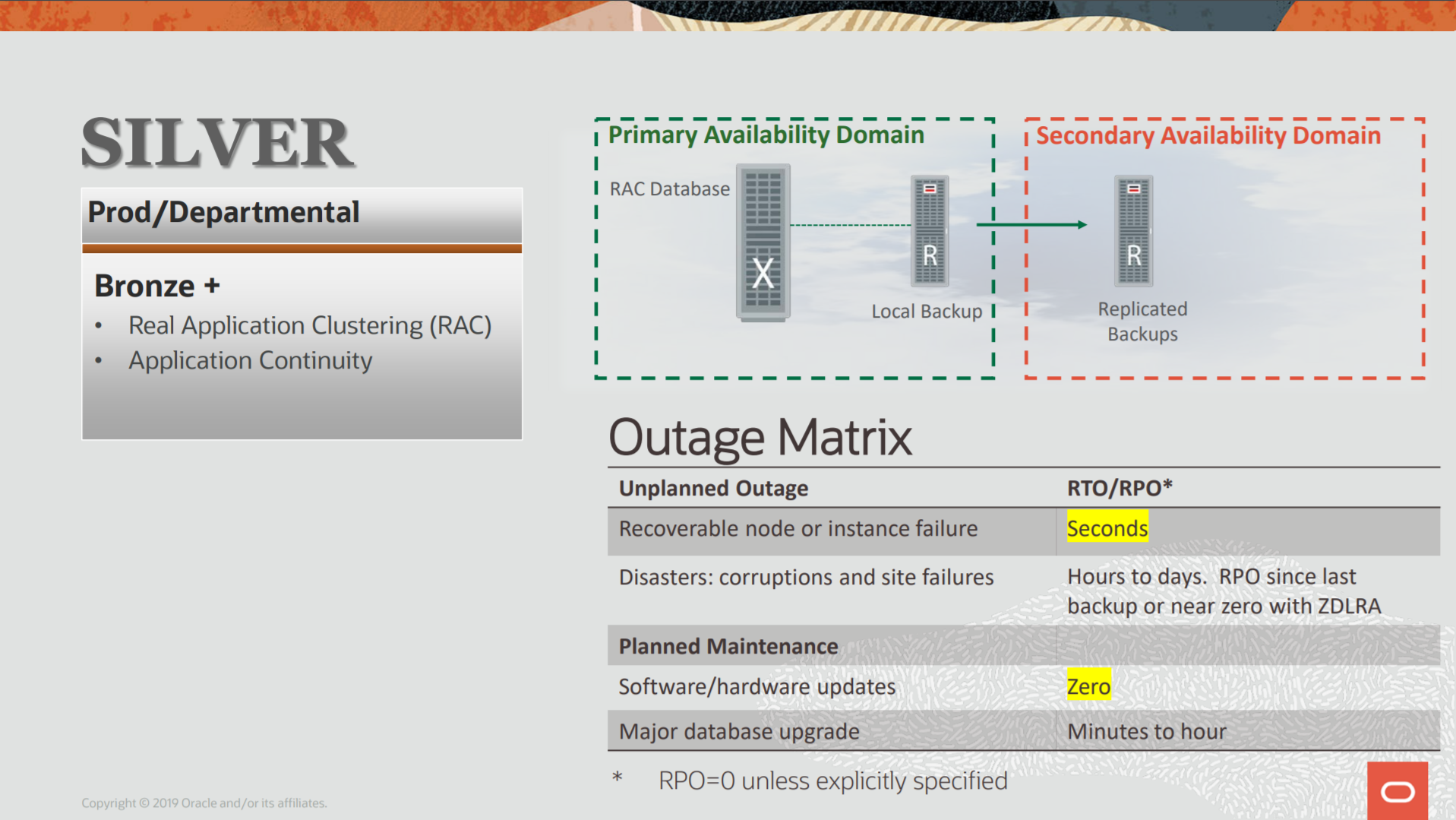
As I wrote previously, sometimes we need to have long-term/archival backups due to some compliance. And usually, these backups are stores outside (like a vault/bunker) but for sure not at the same datacenter as the database. But how we can do this at ZDLRA?
In my post about COPY_BACKUP, I wrote how to have an external copy of one backup set at ZDLRA. But this is not the best option when we need to archive some backup because it continues to follow the same recovery window as the original backup set. This means that if you need to have some kind of archive for 5 years, you need to define your recovery window (at the policy level) to this window. And for sure this will put high pressure on space usage because all backups will be stored until became obsolete.

So, the best way is to use the KEEP backups from rman. And as I wrote in my previous post, they not interact/broke with the incremental forever strategy. Is possible to generate the keep backup, and using the DBMS_RA.MOVE_BACKUP moves these backups to a filesystem destination (and further you can copy/store) and archive it outside of ZDLRA.
Click here to read more…