On 08/March/2023 the Oracle Exadata team released version 23.1.0.0.0 and this include a significant change, OEL 8. But is not just that, other interesting requirements are there and I will discuss them below. I will show you how to patch to the 23.1 version and some other details as well. In this first part, I will just discuss one interesting point that you need to take care of before you start to patch. And probably is more important than you imagine.
Before you patch
The new version brings some requirements (over what you need to be running) to allow you to patch. For the Grid Infrastructure, you need to run 19.15 or a newer version. You can even run the 21c (21.6 or newer) version if you want. If you want to know how to do that, I already discussed how to upgrade both in previous posts (19c, and 21c).
For databases, the recommendation is the same, 19c or 21c. You can still run older versions (11,g, 12c, and 18) but they are already (or will be soon) under Market Driver Support. You can read the MOS note over that (here), but to be clear (now) only the 19c have premier support available.
And now things became quite interesting because the new 23.1 version is the first running with OEL 8. And if you check the supplemental README for the 23.1 version just the 19c support the database and GI are listed. So, be aware and check the compatibilities.
One important detail for this version is that you can only upgrade to 23.1 if your base Exadata running version is newer or equal to 21.2.10 (basically one year old only). If not, you need to upgrade to (at least) this version before you patch to 23.1. And this will be the same in the one-year future, it will be only possible to upgrade to 24.x if you will be running (at least) 23.1.
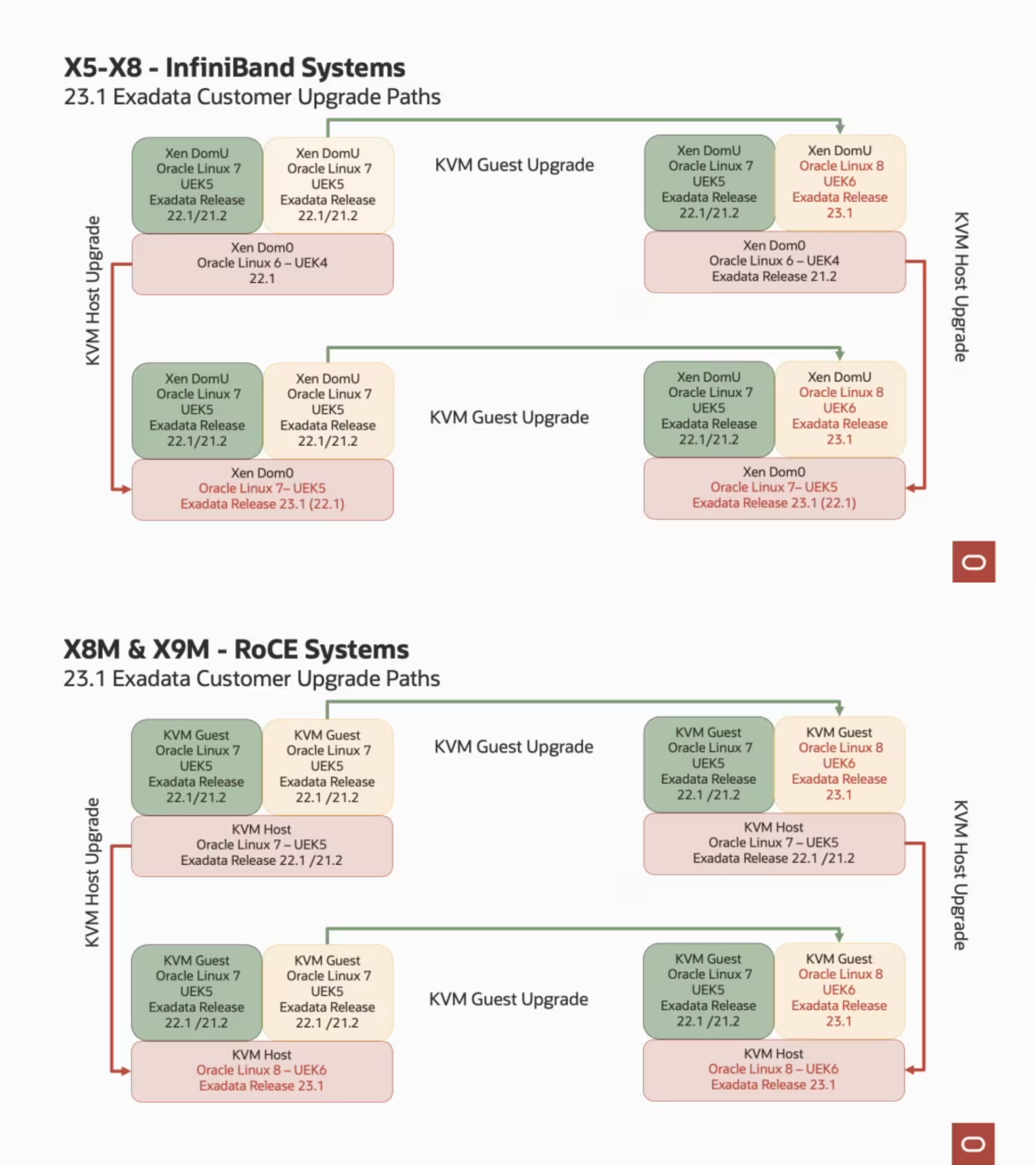
If you are running the old Exadata with InfiniBand, your dom0 will always be updated until Oracle Linux 7 with UEK5. For domU you can upgrade to the OEL 8. And you can upgrade in any order, first dom0 or domU. If you are running RoCE, your dom0 can run the latest OEL 8 UEK6. The blog post from Oracle made an excellent explanation about the upgrade paths and below you can see the images that are there (I used the image from their post).
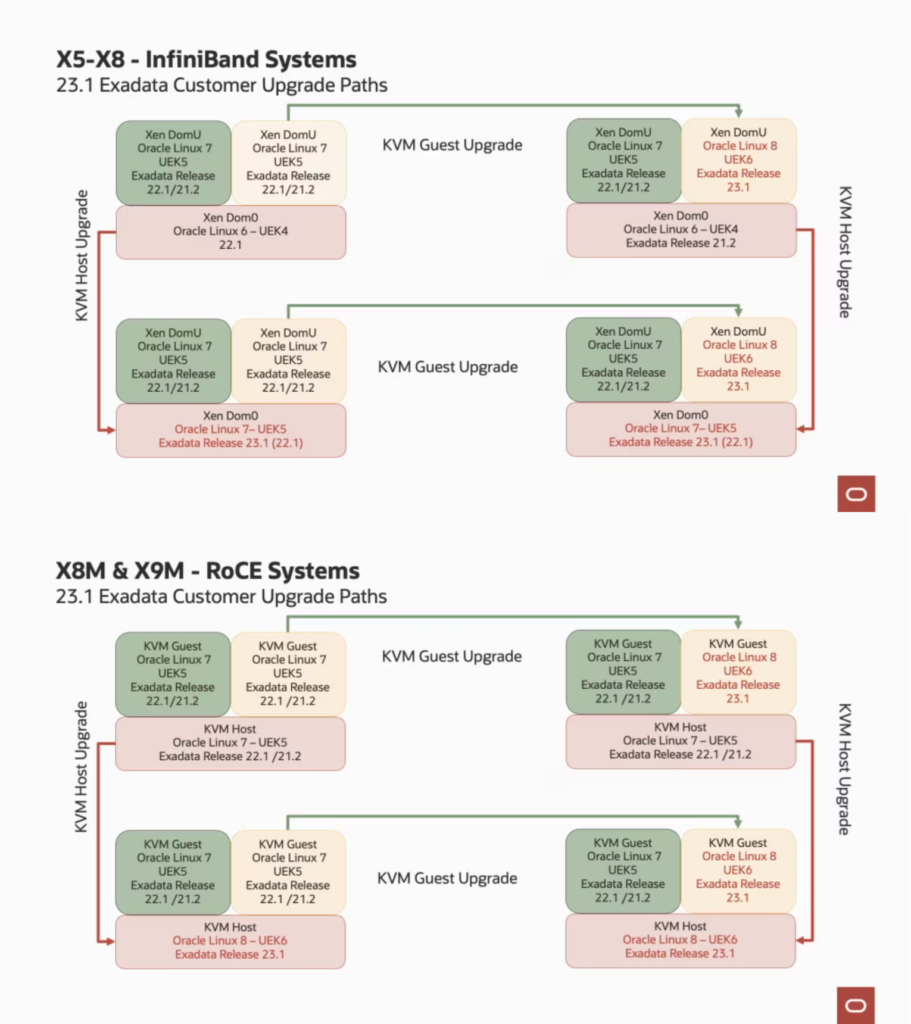
So, as usual, the version includes everything, switches, storage, and database node. And while for switches and storages, the patches are quite normal, for virtualized environments the upgrades paths start to be a little more challenging to plan. I will explain, but (as hinted in the blog post) the upgrade of the Hosts and Guests independently and in any order. And is hard not because of the patch apply itself, but will be to create the plan. Remember the requirements for Oracle Database and GI? So, you can spend a lot of time patching others parts than the Exadata version.
But let’s put pieces together, the small lines written in several places. With this version 23.1, Oracle is telling you that you need to be running at least the Oracle Database 19c to be allowed to have a continuous upgrade for future releases (and possible usage) of Exadata. And whatever the machine version that you use, IB or RoCE network. You can’t anymore use GI older than 19.15, and the databases are enforced, as well, to be this version too. Imagine that you have some kind of incapability between 11g/12c and OEL 8, if you need to open one SR, you need to have/pay for that support, and will not be cheap.
And if you think the upcoming 23c (and that it will be the new LTS version) being in OEL 8 is a requirement. Imagine one year in the future, when the Exadata 24.x version will arrive, do you think that Oracle still supports 11g to the new OEL 9? I don’t think so.
And by the way, IMHO you should be running to 19c. 11G is from 2009, 12.1 from July 2013. So, they are old and out of support for good reasons. I understand the point that they are working on and the legacy applications that maybe you have. But the point is not just to support them, is the case to be possible to continue to upgrade/update your Exadata. Please do not postpone your database upgrades anymore, for the good sake of your Exadata.
Click here to read more…